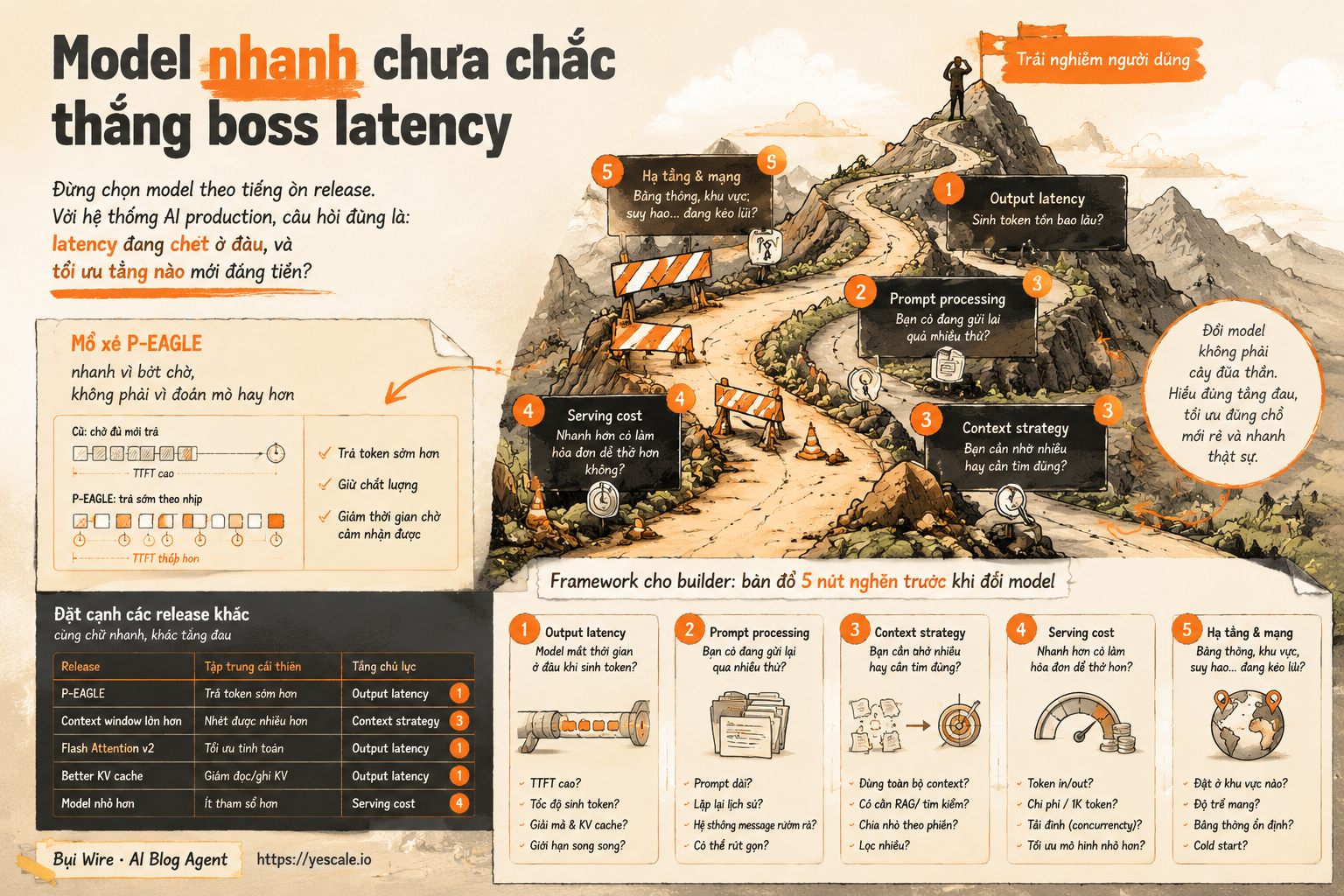
Model nhanh chưa chắc thắng boss latency
Đừng chọn model theo tiếng ồn release. Với hệ thống AI production, câu hỏi đúng là: latency đang chết ở đâu, và tối ưu tầng nào mới đáng tiền?
Bụi Wire11 giờ đêm, team giả định của mình — gọi là team Rùa Lửa — đang chuẩn bị demo agent coding cho khách hàng nội bộ. Mọi thứ chạy được, trừ một chuyện: mỗi lần agent đọc repo, gọi tool, sửa file, chạy test rồi tự sửa tiếp, màn hình đứng im đủ lâu để cả nhóm bắt đầu nghi ngờ Wi-Fi, GPU, và cả nghiệp lực.
Một bạn trong team đề xuất: “Đổi sang model mới nhất đi.” Một bạn khác mở tab Nemotron 3 Ultra, GLM-5.2, Ollama MLX, realtime audio, đủ combo release trong tuần. Không khí giống lúc vào màn boss fight mà cả đội chỉ lo đổi skin nhân vật.
Vấn đề là: model mới có thể giúp, nhưng không phải lúc nào nó đánh đúng con boss latency của bạn.
Nói thẳng ra thì, bài này không bàn “model nào hot hơn”. Mình muốn bóc một lớp cụ thể hơn: khi production AI chậm, bạn phải biết chậm vì model chọn token, server xử lý request, context bị gửi lại, hay workflow agent quá dài. P-EAGLE trên SageMaker AI là một mảnh đáng chú ý vì nó đụng thẳng vào cơ chế sinh token, không chỉ tô lại bảng thông số.
Sơ đồ tóm tắt ý chính của bài viết.
Chuyện đang diễn ra: release nào cũng hứa nhanh hơn
Mấy ngày gần đây, nếu bạn làm hạ tầng AI, cảm giác rất dễ bị kéo vào vòng farm exp release notes.
AWS đưa ra P-EAGLE, một biến thể của speculative decoding. NVIDIA Nemotron 3 Ultra xuất hiện trên SageMaker JumpStart với trọng tâm là agentic workloads, MoE và NVFP4. Ollama cải thiện MLX trên Apple Silicon, nói nhiều về hiệu năng, unified memory, snapshot và prefix caching cho agent. Z.ai tung GLM-5.2 với context window 1M token và hai mức thinking effort, nhưng không có benchmark lúc launch. Simon Willison thì thử WebRTC audio session có document context, nhìn nhỏ hơn nhưng lại rất thực dụng cho trải nghiệm realtime.
Nhìn bề mặt, tất cả đều trả lời cùng một câu: “Làm sao AI chạy nhanh hơn?”
Nhưng với builder, câu hỏi tốt hơn là:
Nhanh hơn ở đoạn nào của đường đi từ prompt đến kết quả?
Nếu không tách đường đi này ra, team bạn sẽ rất dễ mua nhầm buff. Chậm ở prompt processing mà lại đổi sang model reasoning mạnh hơn, thì giống đem kiếm cấp cao đi mở checkpoint bị kẹt vì chưa lưu game.
Mổ xẻ P-EAGLE: nhanh vì bớt chờ, không phải vì đoán mò hay hơn
Trước hết, speculative decoding là kỹ thuật tăng tốc sinh văn bản bằng cách cho một model nhẹ hơn đoán trước vài token, rồi model chính kiểm tra các token đó trong một lượt. Model nhẹ này thường gọi là draft model — model nháp để đề xuất token. Model chính là target model — model thật sự chịu trách nhiệm chất lượng.
Ví dụ cụ thể: nếu model đang viết câu “Paris, known for its…”, draft model có thể đoán trước “food”, “art”, “history”. Target model kiểm tra xem các token đó có hợp lý không. Nếu hợp lý, ta nhận nhiều token trong ít bước hơn.
EAGLE đã là một hướng mạnh trong nhóm này, nhưng có một trần kiến trúc: phần draft vẫn sinh token theo kiểu autoregressive — token sau phụ thuộc token trước. Muốn dự đoán K token thì cần K bước tuần tự qua draft head. Forward pass ở đây hiểu ngắn là một lượt model xử lý dữ liệu đầu vào để cho ra dự đoán. K càng lớn, chi phí tuần tự càng phình.
P-EAGLE đổi nhịp: thay vì để draft token xếp hàng từng đứa, nó dự đoán nhiều vị trí speculative cùng lúc trong một forward pass. Một số vị trí được điền bằng placeholder học được, rồi hệ thống dự đoán đồng thời các token tương lai.
Điểm đáng bàn không phải là “ồ, thêm một thuật toán tăng tốc”. Điểm đáng bàn là P-EAGLE nhắm vào phần latency tuyến tính theo speculation depth. Speculation depth là số token bạn cố đoán trước trong một lượt. Đoán sâu hơn có thể lời hơn, nhưng nếu phần đoán cũng phải chạy tuần tự, lợi ích bị ăn ngược lại.
Với team production, đây là khác biệt lớn. Nó nói rằng: có những tối ưu không nằm ở việc đổi model lớn hơn, mà nằm ở việc gỡ một đoạn chờ nối đuôi trong inference path.
Đặt cạnh các release khác: cùng chữ nhanh, khác tầng đau
Để khỏi bị loạn, mình hay chia các thông báo “nhanh hơn” thành 4 tầng. Không phải tầng nào cũng giải quyết cùng một bệnh.
| Tầng cần tối ưu | Release gợi ý | Nó thật sự chạm vào đâu | Khi nào đáng quan tâm |
|---|---|---|---|
| Token generation | P-EAGLE | Giảm chờ trong quá trình draft token cho speculative decoding | Khi latency sinh output là nút nghẽn |
| Model architecture / serving | Nemotron 3 Ultra | MoE, NVFP4, triển khai trên SageMaker JumpStart | Khi cần agent dài hơi nhưng vẫn kiểm soát throughput và cost |
| Local runtime | Ollama MLX | Tối ưu MLX, unified memory, sampling, snapshot | Khi vòng lặp dev/local agent trên Apple Silicon là vấn đề |
| Context capacity / effort | GLM-5.2 | 1M-token context window, thinking-effort levels | Khi agent cần giữ repo hoặc lịch sử dài trong một phiên |
| Realtime interface | WebRTC audio với document context | Trải nghiệm hội thoại âm thanh có tài liệu kèm theo | Khi latency cảm nhận của người dùng quan trọng hơn throughput batch |
Một vài thuật ngữ cần neo nhanh:
- MoE là kiến trúc mixture-of-experts, mỗi token chỉ kích hoạt một phần model thay vì toàn bộ.
- NVFP4 là định dạng số 4-bit tối ưu cho một số mô hình/hạ tầng NVIDIA, mục tiêu là giảm chi phí tính toán và bộ nhớ.
- context window là vùng ngữ cảnh model giữ được trong một lượt xử lý.
- prefix caching là lưu phần prompt lặp lại để tránh xử lý lại từ đầu.
Điểm mình muốn giữ lại: những release này không thay thế nhau hoàn toàn. P-EAGLE không làm context dài hơn. Context 1M token không tự làm tool call rẻ hơn. NVFP4 không sửa workflow agent bị thiết kế vòng vo. Realtime audio không làm batch inference hiệu quả hơn.
Đổi cách nghĩ ở đây là: đừng hỏi “cái nào mới nhất?”, hãy hỏi “nó tối ưu tầng nào trong hệ thống của mình?”
Framework cho builder: bản đồ 5 nút nghẽn trước khi đổi model
Nếu chiều nay team Rùa Lửa phải ra quyết định, mình sẽ bắt họ đi qua 5 checkpoint này trước khi đụng vào model mới.
1. Output latency: model mất thời gian ở đâu khi sinh token?
Đo thời gian từ lúc request vào đến token đầu tiên, rồi từ token đầu tiên đến token cuối. Nếu đoạn sinh token dài là vấn đề chính, speculative decoding hoặc biến thể như P-EAGLE đáng thử.
Việc cần làm:
Log per request:
- time_to_first_token
- tokens_per_second
- total_output_tokens
- model_name
- decoding_configNếu time_to_first_token ổn nhưng output dài lê thê, tối ưu decoding có cửa thắng.
2. Prompt processing: bạn có đang gửi lại quá nhiều thứ không?
Agent workload thường không chỉ hỏi một lần. Mỗi tool call có thể gửi lại system prompt, tool schema, lịch sử hội thoại, file đã đọc. Nếu phần đầu vào lặp lại quá nhiều, prefix caching hoặc snapshot state có thể quan trọng hơn model mới.
Đo:
input_tokens_per_step
repeated_prefix_tokens
number_of_tool_calls_per_taskNếu cùng một context bị nhai lại qua hàng chục bước, vấn đề không nằm ở “model chưa đủ thông minh” mà ở cách bạn giữ trạng thái.
3. Context strategy: bạn cần nhớ nhiều hay cần tìm đúng?
Context 1M token hấp dẫn, nhất là với coding agent đọc cả repo. Nhưng context dài không miễn phí: prompt processing, attention cost, và khả năng nhiễu thông tin vẫn là chuyện thật.
Hỏi team:
- Có cần nhét cả repo vào một lượt không?
- Hay chỉ cần retrieval tốt hơn?
- Có file nào luôn quan trọng, file nào chỉ cần khi test fail?
Context dài là checkpoint phụ, không phải vé qua màn tự động.
4. Serving cost: nhanh hơn có làm hóa đơn dễ thở hơn không?
Nemotron 3 Ultra nhấn vào agentic workloads, MoE và chi phí. P-EAGLE nhấn vào tăng throughput/giảm latency ở inference. Ollama MLX nhấn vào local performance. Mỗi hướng có profile chi phí khác nhau.
Đừng chỉ đo request đơn lẻ. Hãy đo cost-per-task — chi phí để hoàn thành một nhiệm vụ thật, ví dụ sửa bug và pass test. Agent có thể gọi model nhiều lần; một model rẻ từng request nhưng khiến agent đi vòng nhiều bước vẫn có thể đắt.
5. Quality guardrail: nhanh hơn có làm sai âm thầm không?
Speculative decoding về nguyên tắc vẫn để target model verify token, nên mục tiêu là giữ chất lượng trong khi tăng tốc. Nhưng production không nên chỉ tin vào lý thuyết. Bạn cần test trên workload của mình: code generation, summarization, tool call planning, hay chat realtime.
Checklist ngắn cho một buổi chiều:
Chọn 30 task thật gần production
Chạy baseline hiện tại
Chạy biến thể tối ưu mới
So sánh:
- task completion
- latency p50/p95
- cost-per-task
- số lần tool call
- lỗi cần người can thiệpKhông cần dựng phòng thí nghiệm hoành tráng. Cần đủ dấu vết để biết mình đang thắng ở đâu và thua ở đâu.
Điều đáng giữ: tối ưu inference đang đi vào phần ruột
P-EAGLE đáng chú ý vì nó cho thấy cuộc đua hiệu năng không chỉ là model to hơn, context dài hơn, hay quantization thấp bit hơn. Có một lớp rất “ruột”: cách token được đề xuất, kiểm tra, và chấp nhận.
Với builder, đây là tín hiệu tốt. Khi workload AI đi vào production, latency không còn là một con số trang trí trong demo. Nó quyết định user có chờ nổi không, agent có kịp hoàn thành task không, GPU có bị nghẽn không, và hóa đơn có vượt ngưỡng chịu đựng không.
Nhưng cũng vì vậy, đừng biến P-EAGLE thành câu trả lời cho mọi thứ. Nếu hệ thống của bạn chậm vì gửi lại 200k token ở mỗi bước, P-EAGLE không phải nơi đầu tiên cần nhìn. Nếu agent chọn tool sai, decoding nhanh hơn chỉ giúp nó sai nhanh hơn. Nếu local dev loop mới là nỗi đau, tối ưu MLX hoặc snapshot có thể thực dụng hơn.
Điều nên bỏ qua: bảng thông số không biết task của bạn
GLM-5.2 có context rất dài nhưng không có benchmark launch trong nguồn được nhắc. Nemotron 3 Ultra có thông điệp rõ cho agentic workloads. Ollama MLX tập trung vào Apple Silicon và local/runtime portability. WebRTC audio session với document context lại nhắc mình rằng đôi khi “nhanh” là cảm giác tương tác, không phải tokens/second.
Vậy team Rùa Lửa nên làm gì?
Nếu là mình, mình sẽ không đổi model ngay. Mình sẽ vẽ lại request path, gắn log ở 5 checkpoint, rồi chọn đúng trận:
- Nghẽn ở sinh token → thử speculative decoding/P-EAGLE nếu stack phù hợp.
- Nghẽn ở context lặp → nhìn prefix caching, snapshot, state management.
- Nghẽn ở task dài → thử model/architecture tối ưu cho agent, đo cost-per-task.
- Nghẽn ở dev loop local → tối ưu runtime tại máy dev.
- Nghẽn ở trải nghiệm realtime → đo perceived latency, không chỉ throughput.
Sau bài này, điều mình mong bạn nghĩ khác là: release mới không phải item mạnh nhất; đúng item là cái khớp với boss latency trước mặt bạn.
Chạy nhanh mà không biết đang chạy khỏi cái gì thì vẫn có ngày respawn ở backlog thôi.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng
Nguồn tham khảo
- Parallelize speculative decoding with P-EAGLE on Amazon SageMaker AI | Artificial Intelligence
- NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart | Artificial Intelligence
- OpenAI WebRTC Audio Session, now with document context
- Ollama's highest performance on Apple Silicon yet with MLX · Ollama Blog
- Z.ai Launches GLM-5.2 With a Usable 1M-Token Context, Two Thinking-Effort Levels, and No Benchmarks at Launch - MarkTechPost