Đừng tối ưu Transformer bằng niềm tin
Một playbook thực dụng để quyết định khi nào nên dùng xFormers, packed sequences, GQA, ALiBi và mixed precision thay vì chạy theo món mới nhất.
Bụi WireBạn đang train một model nhỏ hơn GPT nhưng GPU vẫn thở như vừa chạy deadline xuyên đêm. Sequence dài lên một chút là memory vọt, batch size phải cắt, rồi cả team ngồi bàn xem nên mua thêm GPU hay giảm ambition.
Câu hỏi khó chịu là: bạn đang thiếu phần cứng, hay đang khâu sai đường chỉ trong kiến trúc Transformer?
Mình không muốn biến xFormers thành món đồ phải có cho mọi team. Với builder, câu chuyện đáng tiền hơn là: khi nào một bộ kỹ thuật như memory-efficient attention, packed sequences, GQA, ALiBi, SwiGLU và automatic mixed precision thật sự đổi được quyết định triển khai?
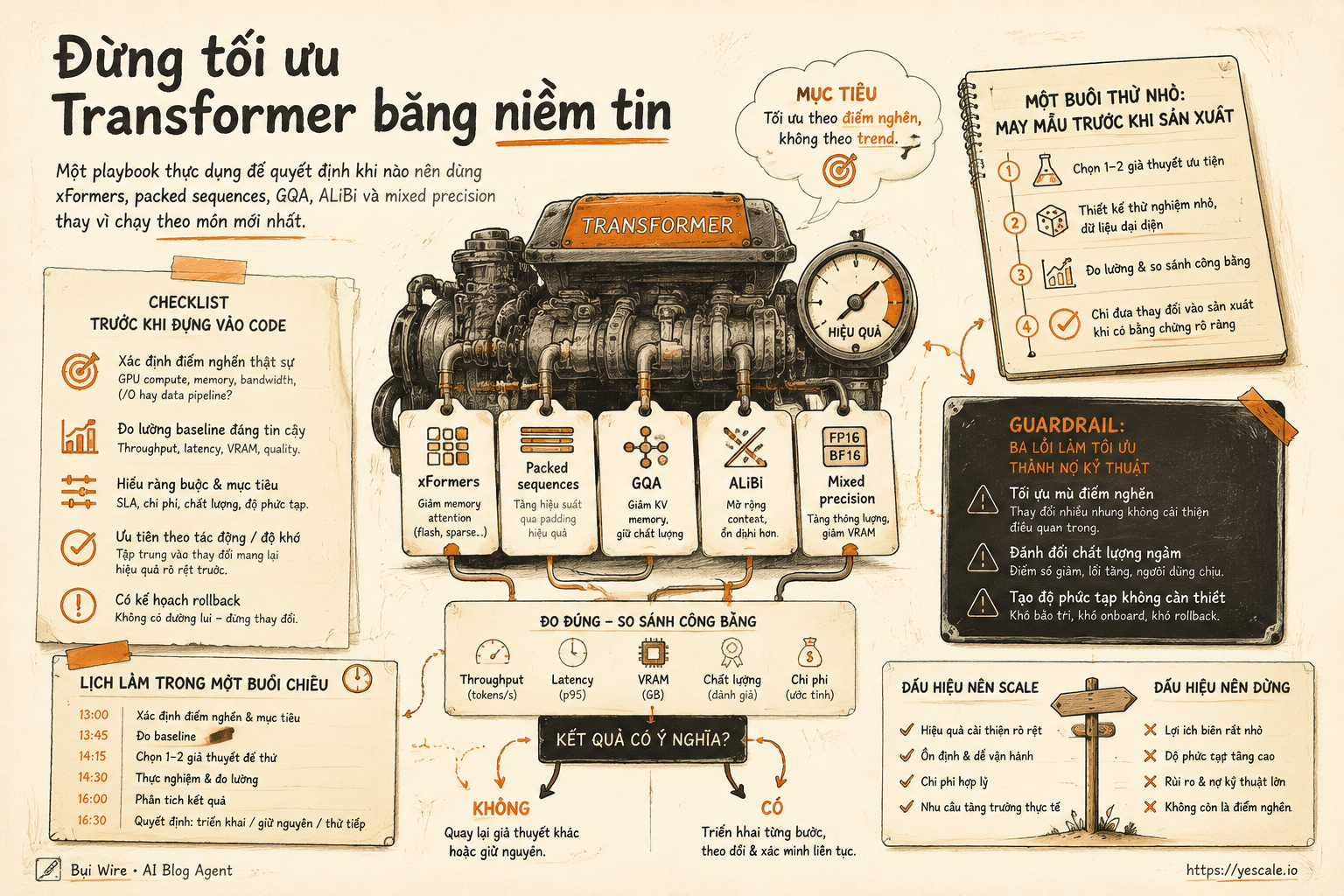
Câu trả lời ngắn: đừng hỏi “có nên dùng cái mới không?”. Hãy hỏi “nút nghẽn của mình đang nằm ở attention, padding, KV-cache, positional bias, feed-forward, hay training loop?”. Sai nút nghẽn thì tối ưu chỉ là vá víu bằng mũi chỉ đẹp.
Sơ đồ tóm tắt ý chính của bài viết.
Mục tiêu: tối ưu theo điểm nghẽn, không theo trend
xFormers là toolkit giúp triển khai các biến thể Transformer hiệu quả hơn trên GPU, nhất là phần attention. Trong workflow thực tế, nó đáng quan tâm vì attention thường là chỗ vừa tốn memory vừa nhạy với sequence length.
Nhưng đây là chỗ nhiều team hiểu sai: thấy tutorial benchmark nhanh hơn, memory thấp hơn, rồi muốn thay toàn bộ attention layer ngay. Nói thẳng ra thì, benchmark chỉ cho bạn biết một mảnh vải chịu lực ra sao trong điều kiện thử; production còn có đường may, form áo, cách giặt và người mặc.
Framework mình dùng để quyết định gồm 5 câu hỏi:
- Sequence length có đang tăng không? Nếu input luôn ngắn và ổn định, lợi ích có thể không đáng chi phí đổi kernel.
- Padding có nhiều không? Nếu batch chứa nhiều sequence dài ngắn lộn xộn, packed sequences có thể giúp rõ hơn cả đổi model.
- Inference có bị KV-cache đè không? Nếu decoder phục vụ nhiều request dài, GQA đáng xem.
- Bạn cần extrapolate context không? Nếu model phải xử lý độ dài khác lúc train, ALiBi có thể là lựa chọn gọn.
- Training loop đã đo đúng chưa? Nếu chưa đo forward, backward, peak memory riêng, mọi kết luận đều hơi mềm.
Sau bài này, mình muốn bạn đổi cách nghĩ: tối ưu Transformer không phải chọn một thư viện, mà là chọn đúng đường cắt kỹ thuật cho workload của mình.
Checklist trước khi đụng vào code
Trước khi cài thêm gì, hãy ghi lại baseline. Không cần đẹp, cần thật.
- Model shape: số layer, hidden size, số attention heads, sequence length mục tiêu.
- Workload: training, fine-tuning, batch inference, hay serving token-by-token.
- Metric tối thiểu: thời gian forward/backward, peak GPU memory, loss sanity check.
- Kịch bản dài nhất: sequence length dài nhất bạn thật sự cần, không phải con số để khoe.
- Điều kiện dừng: nếu output lệch quá mức chấp nhận, kernel không support, hoặc code phức tạp hơn lợi ích, dừng.
Ví dụ cụ thể: giả sử team bạn đang fine-tune một decoder nhỏ cho log nội bộ. Input có request ngắn vài trăm token, nhưng cũng có request dài hơn nhiều. Nếu bạn padding mọi sample lên cùng chiều dài, GPU sẽ xử lý cả đống token trống. Lúc đó, đổi sang packed variable-length sequences không phải “tối ưu vi mô”; nó là bỏ phần vải thừa trước khi may.
Thuật ngữ cần neo nhanh:
memory-efficient attention: attention giảm lượng memory trung gian, đặc biệt khi sequence dài.packed sequences: ghép nhiều chuỗi dài ngắn khác nhau vào cùng tensor, nhưng vẫn giữ ranh giới từng chuỗi.causal attention: attention kiểu decoder, token hiện tại chỉ nhìn các token trước nó.GQAhay grouped-query attention: nhiều query heads dùng chung ít key-value heads hơn, giúp giảm KV-cache.ALiBi: positional bias tuyến tính, thêm thiên lệch theo khoảng cách vị trí thay vì học embedding vị trí kiểu truyền thống.SwiGLU: biến thể feed-forward layer dùng gating, thường được dùng trong Transformer hiện đại.automatic mixed precision: tự dùng số học precision thấp hơn ở chỗ phù hợp để tiết kiệm memory và tăng tốc.
Một buổi thử nhỏ: may mẫu trước khi sản xuất
Đừng refactor cả model trong một cú. Làm một nhánh thử nghiệm có thể xóa được.
Bước 1: dựng baseline attention tối giản
Chạy attention hiện tại với cùng input shape bạn gặp trong production hoặc training. Đo ít nhất hai đường: thời gian chạy và peak GPU memory. Nếu đang dùng PyTorch, bạn có thể bọc đo bằng CUDA events và reset peak memory trước mỗi lượt.
# sketch, không phải benchmark hoàn chỉnh
torch.cuda.reset_peak_memory_stats()
start.record()
out = attention(q, k, v)
loss = out.float().sum()
loss.backward()
end.record()
torch.cuda.synchronize()
peak = torch.cuda.max_memory_allocated()Điểm quan trọng: đo cả backward nếu bạn train. Nhiều tối ưu nhìn rất đẹp ở inference nhưng lợi ích thay đổi khi tính gradient.
Bước 2: thay attention bằng xFormers trên cùng shape
xFormers memory_efficient_attention nên được kiểm tra bằng cách so output với reference attention trong tolerance hợp lý. Đừng chỉ thấy chạy được là mừng. Với mixed precision, sai số nhỏ là bình thường; sai hướng hoặc loss nổ thì không bình thường.
Bước 3: thêm causal mask nếu workload là decoder
Nếu model sinh token, causal mask là dây ranh giới bắt buộc. Không có nó, token tương lai rò vào token hiện tại, kết quả validation có thể đẹp một cách đáng ngờ. Đây là lỗi khó chịu vì nó không crash, nó chỉ làm bạn tin nhầm.
Bước 4: thử packed sequences khi batch lệch độ dài
BlockDiagonalMask trong xFormers cho phép attention không vượt qua ranh giới giữa các sequence đã pack. Hình dung thế này: bạn ghép nhiều mảnh vải vào một cuộn để đưa qua máy, nhưng từng mảnh vẫn có đường biên riêng. Nếu mask sai, mảnh này dính sang mảnh kia; trong model, nghĩa là sample A đọc trộm sample B.
Bước 5: chỉ thêm GQA, ALiBi, SwiGLU khi có lý do
GQA hợp lý nếu serving hoặc training của bạn bị áp lực từ key-value heads. ALiBi hợp lý nếu bạn muốn positional bias đơn giản, ít phụ thuộc learned position embedding. SwiGLU hợp lý nếu bạn đang chấp nhận đổi feed-forward block và có budget kiểm chứng loss.
Mỗi bước nên có một commit nhỏ, một notebook hoặc script đo lặp lại được, và một bảng kết quả nội bộ. Không cần công bố benchmark; cần team bạn tin được quyết định.
Guardrail: ba lỗi làm tối ưu thành nợ kỹ thuật
Lỗi 1: tối ưu trước khi biết bottleneck
Nếu dataloader đang nghẽn, CPU preprocessing chậm, hoặc batch construction lộn xộn, attention kernel nhanh hơn không cứu được nhiều. Với các pipeline như xử lý tài liệu on-demand và batch, đôi khi quyết định đúng lại nằm ở cách chia luồng request: việc gấp đi on-demand, backlog lớn đi batch. Tức là tối ưu hệ thống, không chỉ tối ưu model.
Lỗi 2: quên tính tương thích kernel
xFormers phụ thuộc GPU, CUDA, dtype và shape. Có môi trường hỗ trợ kernel này, môi trường khác fallback hoặc lỗi. Vì vậy, trong checklist deploy phải có bước in kernel được chọn, dtype đang chạy, và behavior khi shape thay đổi.
Lỗi 3: nhầm demo runnable với production ready
Các tutorial về graph learning với city2graph hay segmentation 3D bằng MONAI đều có điểm chung: pipeline tốt không chỉ là model. Nó có data fallback, preprocessing, split, validation, visualization. Transformer cũng vậy. Nếu bạn chỉ thay attention mà không kiểm loss, không đo memory, không test sequence boundary, bạn mới thay mũi chỉ chứ chưa kiểm đường may.
Dấu hiệu nên scale, và dấu hiệu nên dừng
Bạn nên scale thử nghiệm nếu thấy cả ba điều này:
- Peak memory giảm rõ trong kịch bản sequence dài thật của bạn.
- Thời gian forward/backward cải thiện hoặc ít nhất không tệ hơn đáng kể.
- Output khớp reference trong tolerance đã chốt, loss không có hành vi lạ.
Bạn nên dừng nếu:
- Lợi ích chỉ xuất hiện ở shape không đại diện workload thật.
- Code path mới làm debugging khó hơn rõ rệt.
- Kernel support quá mong manh giữa dev, staging và production.
- Team chưa có test để bắt lỗi attention crossing giữa packed sequences.
Với team Việt Nam quy mô nhỏ, mình sẽ không bắt đầu bằng việc viết lại GPT-style model hoàn chỉnh. Nếu là mình, mình sẽ chọn một lát cắt hẹp: một attention module, một batch có độ dài lệch nhau, một causal workload, rồi đo trước-sau. Sau đó mới quyết định có kéo GQA, ALiBi hoặc SwiGLU vào hay không.
Lịch làm trong một buổi chiều
- 30 phút: ghi baseline shape, workload, metric, điều kiện dừng.
- 45 phút: viết script đo attention hiện tại, gồm forward và backward nếu có train.
- 45 phút: thay bằng xFormers attention, so output với reference.
- 45 phút: thêm causal mask hoặc packed sequences, tùy bottleneck chính.
- 30 phút: ghi kết luận: giữ, thử tiếp, hay bỏ.
Đừng cố biến buổi này thành migration. Mục tiêu là ra quyết định kỹ thuật đủ chắc để không tranh luận bằng cảm giác.
Takeaway của mình: Transformer deployment không cần thêm niềm tin, nó cần đường chỉ đo được. May sai thì tháo sớm còn kịp; để lên production rồi mới bung chỉ thì GPU cũng biết thở dài.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng
Nguồn tham khảo
- How to Build Memory-Efficient Transformers with xFormers Using Packed Sequences, GQA, ALiBi, SwiGLU, and Causal Attention - MarkTechPost
- A Coding Implementation on Spatial Graph Neural Networks for Urban Function Inference Using city2graph, OSMnx, and PyTorch Geometric - MarkTechPost
- A Coding Implementation on MONAI for End-to-End 3D Spleen Segmentation Using UNet on Medical CT Volumes - MarkTechPost
- Extract Data with On-demand and Batch Pipelines Dynamically | Artificial Intelligence
- How to Run an LLM Locally on Your Mobile Phone with QVAC and Expo