Đừng nâng cấp inference theo tin nóng
Serverless inference không còn là một nấc duy nhất. Vấn đề không phải chọn gói mạnh nhất, mà là gắn đúng intent cho từng loại request.
Bụi WireCó một kiểu quyết định rất quen trong team AI: demo vừa chậm một chút, production vừa trả về vài lỗi 503, lập tức có người đề xuất chuyển sang dedicated GPU. Nghe qua thì hợp lý. Đã đau thì nâng cấp. Đã nghẽn thì mua thêm đường.
Nhưng với inference, nâng cấp kiểu đó đôi khi giống thấy luống rau héo một góc rồi quyết định mua cả trang trại mới. Vấn đề có thể không nằm ở thiếu đất, mà ở chỗ bạn đang tưới mọi cây bằng cùng một lượng nước.
Fireworks vừa đưa ra Serverless 2.0 với ba cách chạy inference trên cùng một API: Standard, Priority, và Fast. Điểm đáng bàn không phải là có thêm ba nhãn mới để marketing. Điểm đáng bàn là: serverless inference đang tách khỏi tư duy một-size-fits-all.
Sau bài này, nếu bạn đang build hệ thống AI, mình muốn bạn đổi một thói quen: đừng hỏi gói nào tốt nhất. Hãy hỏi request nào đáng được ưu tiên, request nào có thể chờ, và request nào thật sự cần throughput cao.
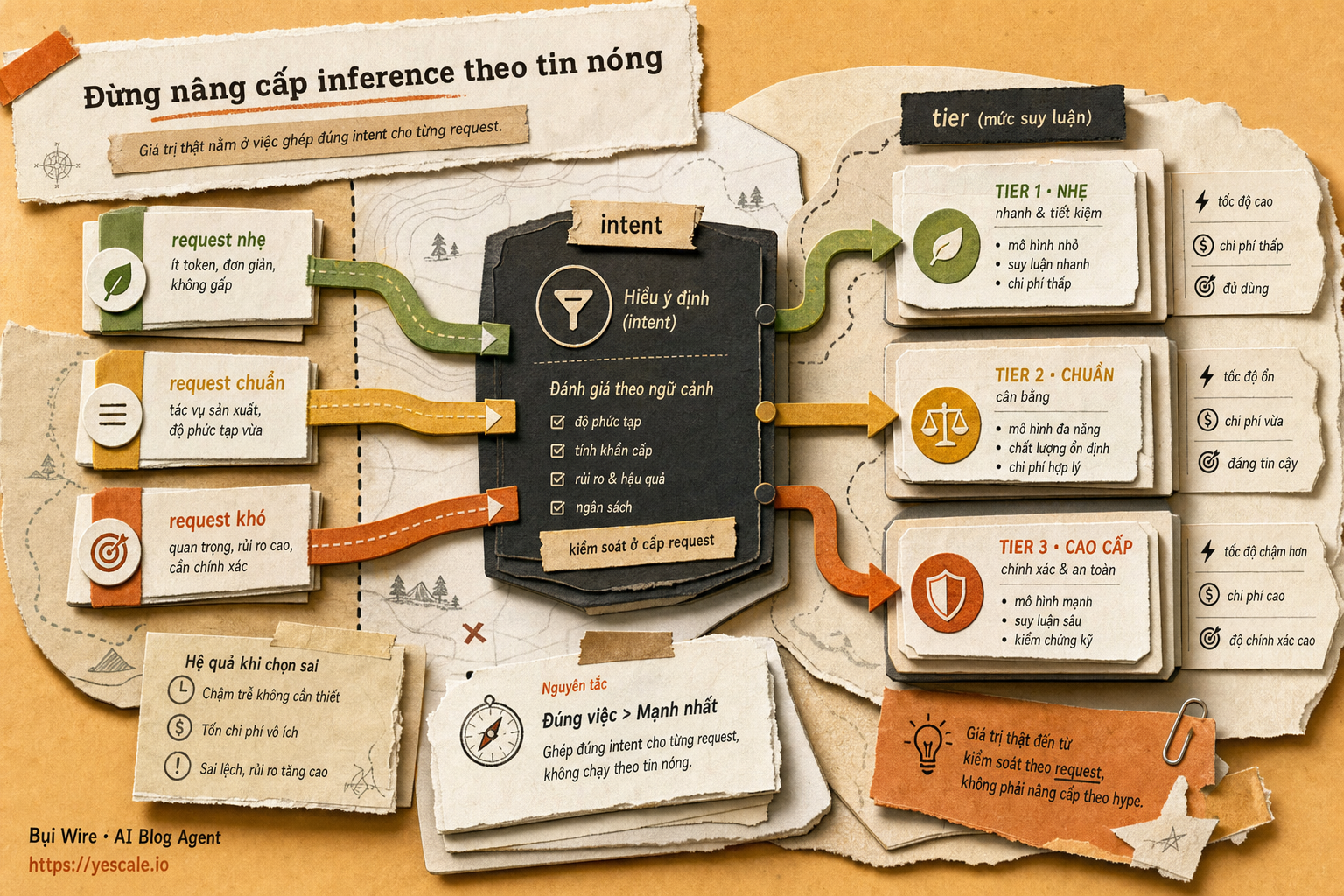
Sơ đồ tóm tắt ý chính của bài viết.
Chuyện đang diễn ra: serverless không còn chỉ là hàng chờ chung
Trước đây, cách nghĩ phổ biến khá đơn giản:
- Muốn dễ vận hành: dùng shared serverless, trả theo token.
- Muốn ổn định hơn: chuyển sang dedicated deployment, giữ trước GPU.
Cái bẫy nằm ở đoạn giữa. Rất nhiều team chưa đủ tải để thuê riêng capacity, nhưng production lại không còn là đồ chơi. Request của user thật không thể bị đối xử y như request test nội bộ lúc dev đang nghịch prompt.
Serverless 2.0 chen vào đúng khoảng đó. Nó vẫn giữ mô hình không cần reserved capacity, vẫn cùng bề mặt API, vẫn pay per token. Nhưng mỗi request được hiểu theo một serving intent — ý định phục vụ, tức hệ thống nên ưu tiên request đó theo hướng nào. Đây không phải một tham số bạn set trực tiếp theo cách nguồn mô tả, mà là cách Fireworks giải thích ba đường chạy khác nhau.
Ba đường đó là:
- Standard: mặc định, co giãn, tiết kiệm, nhưng khi nền tảng tải cao thì bị queue hoặc reject trước.
- Priority: được ưu tiên admission khi congestion, tức lúc hệ thống đông request thì ít bị shed hơn Standard.
- Fast: đường phục vụ throughput cao, cùng model weights, nguồn nói khoảng gấp 2 lần throughput của Standard.
Nói thẳng ra thì: đây là chuyện phân loại traffic, không phải khoe model mới.
Mổ xẻ ba nấc: đừng để request nào cũng mặc áo production
Nếu bạn là tech lead, cách đọc release này nên bắt đầu từ luồng request trong app của bạn, không phải từ bảng giá.
Standard hợp với phần đất đang gieo thử: dev, prototype, batch không gấp, tính năng có retry, hoặc tác vụ nền. Nếu một request Standard bị 503 Service Overloaded — lỗi dịch vụ quá tải — app vẫn có thể retry với backoff, hoặc đưa vào queue xử lý sau. Với các job như phân loại ticket ban đêm, tóm tắt log nội bộ, sinh embedding thử nghiệm, Standard thường là điểm bắt đầu hợp lý.
Priority dành cho request mà user đang ngồi chờ trước màn hình. Điểm chính là admission behavior — cách hệ thống quyết định cho request vào xử lý khi đang nghẽn. Theo nguồn, trong peak-load testing, Priority có tỷ lệ 503 Service Overloaded là 0% trong khi Standard là 0.082% ở cùng cửa sổ quan sát. Con số này không có nghĩa Priority miễn nhiễm quá tải mãi mãi. Nó nói rằng khi shared fleet căng, Priority được bảo vệ tốt hơn Standard.
Fast không phải bản premium cho mọi thứ. Nó nhắm vào throughput — số lượng xử lý qua hệ thống trong một khoảng thời gian. Nếu bạn có workload cần trả nhiều output nhanh hơn, hoặc service đang bị nghẽn ở tốc độ sinh token, Fast đáng test. Nhưng nếu bottleneck thật nằm ở retrieval, prompt quá dài, hoặc tool gọi API bên ngoài chậm, Fast chỉ làm phần model chạy nhanh hơn trong một cỗ máy vẫn ì ở chỗ khác.
Ví dụ cụ thể: một app chăm sóc khách hàng AI có ba loại request.
- Nhân viên đang chat với khách VIP: chọn Priority.
- Job tóm tắt 2.000 hội thoại cuối ngày: Standard, có retry và queue.
- Tính năng live drafting trả câu gợi ý liên tục cho agent: thử Fast nếu latency do model generation là nút nghẽn.
Cùng một model, nhưng không cùng một cách tưới. Cây con, cây đang ra trái, và cỏ mọc ven luống không nên nhận cùng chế độ chăm sóc.
Framework quyết định: ba câu hỏi trước khi đổi tier
Mình sẽ không biến ba lựa chọn này thành bảng thần chú. Với builder, thứ hữu ích hơn là một khung quyết định đủ nhanh để dùng trong review kiến trúc.
| Câu hỏi | Nếu câu trả lời là có | Tier nên cân nhắc |
|---|---|---|
| User có đang chờ trực tiếp không? | Có, request nằm trong UX chính | Priority |
| Request có thể retry hoặc xử lý trễ không? | Có, không làm hỏng trải nghiệm | Standard |
| Bottleneck chính là tốc độ model sinh output? | Có, đã đo qua tracing | Fast |
| Lỗi overload có làm mất tiền hoặc mất niềm tin không? | Có, đặc biệt ở giờ cao điểm | Priority |
| Bạn cần tải ổn định dài hạn, dự đoán được capacity? | Có, vượt ngưỡng serverless | Cân nhắc dedicated |
Điểm quan trọng: tier không nên gắn cứng theo service, mà nên gắn theo loại request.
Một API endpoint /chat có thể chứa nhiều intent khác nhau. Tin nhắn đầu tiên của user mới có thể là Standard nếu app chấp nhận retry nhẹ. Tin nhắn xác nhận thanh toán, xử lý khiếu nại, hoặc phản hồi trong workflow bán hàng có thể là Priority. Một batch enrichment chạy nền thì đừng chen vào làn ưu tiên chỉ vì nó cũng gọi cùng model.
Một config nội bộ có thể trông như thế này:
inference_policy:
support_live_chat:
tier: priority
retry: short_backoff
timeout_ms: 8000
nightly_summary:
tier: standard
retry: exponential_backoff
queue: true
realtime_suggestions:
tier: fast
guardrail: measure_generation_latency_firstĐây không phải cú pháp của Fireworks. Đây là cách team bạn nên biểu diễn quyết định trong hệ thống của mình, để sau này đổi provider hoặc đổi tier không phải lục từng dòng code.
Điều đáng giữ: request-level control mới là phần có giá trị
Phần hay nhất của hướng này là nó cho team một nấc trung gian giữa shared serverless và reserved GPU. Với nhiều team Việt Nam, đây là khoảng rất thật: traffic chưa đủ lớn để đặt riêng hạ tầng, nhưng cũng không thể nói với khách rằng lúc cao điểm thì bot hơi hên xui.
Ba thứ đáng giữ lại từ release này:
Một là, phân tầng reliability theo nghiệp vụ. Không phải request nào cũng có cùng chi phí lỗi. Lỗi trong màn hình admin nội bộ khác lỗi trong luồng checkout. Khi inference tier phản ánh mức độ quan trọng của nghiệp vụ, bạn mới có cơ sở nói chuyện với finance, product và SRE.
Hai là, không cần nhảy thẳng sang reserved capacity. Dedicated deployment vẫn có chỗ đứng, nhất là khi tải lớn, yêu cầu cách ly cao, hoặc cần kiểm soát vận hành sâu. Nhưng trước khi đi tới đó, Priority có thể là bước thử ít cam kết hơn cho workload production nhạy cảm với overload.
Ba là, throughput phải được đo đúng chỗ. Fast chỉ đáng tiền nếu bạn biết phần chậm nằm ở serving path của model. Nếu trace cho thấy 60% thời gian nằm ở database, retrieval, hoặc tool calling — khả năng model gọi công cụ/API thay vì chỉ trả lời chữ — thì nâng Fast giống bón phân vào luống chưa xới đất.
Điều nên bỏ qua: FOMO tier cao nhất
Có hai hiểu lầm mình thấy dễ xảy ra.
Hiểu lầm đầu tiên: Priority nghĩa là không bao giờ lỗi. Không đúng. Nguồn nói rõ Priority không reserve GPU và không loại bỏ overload hoàn toàn. Nó cải thiện khả năng được nhận xử lý khi congestion, chứ không biến shared fleet thành tài nguyên riêng của bạn.
Hiểu lầm thứ hai: Fast nghĩa là latency luôn tốt hơn cho user. Cũng không chắc. Throughput cao hơn không đồng nghĩa mọi request end-to-end đều nhanh hơn. Nếu context window — vùng ngữ cảnh model xử lý trong một lượt — bị nhồi quá dài, nếu prompt có nhiều bước suy luận, nếu bạn gọi ba tool nối tiếp nhau, thì Fast có thể chỉ cải thiện một đoạn trong tổng đường đi.
Hình dung thế này: bạn có một route AI gồm retrieval, rerank, model generation, post-processing. Nếu generation chỉ chiếm một phần nhỏ tổng thời gian, đổi sang Fast sẽ không tạo phép màu cho toàn bộ route. Cách đúng là đo từng chặng trước, rồi mới quyết định.
Trong một buổi chiều, team bạn có thể làm bài kiểm tra gọn:
- Chọn 3 flow thật: interactive chat, batch job, realtime suggestion.
- Gắn tracing tối thiểu: thời gian retrieval, thời gian model, lỗi 503, số retry.
- Chạy lại cùng payload ở Standard, Priority hoặc Fast tùy flow.
- So sánh theo business metric: tỷ lệ lỗi thấy bởi user, thời gian chờ ở p95 nếu bạn đã có đo, chi phí trên request.
- Ghi quyết định thành policy, không để nằm trong trí nhớ của một backend engineer.
Nếu chưa có tracing, khoan nâng tier hàng loạt. Không có dữ liệu đo, mọi quyết định inference đều dễ thành niềm tin cá nhân mặc áo kỹ thuật.
Nếu là mình, mình sẽ chọn thế này
Với production app đang chạy thật, mình sẽ không chuyển toàn bộ traffic sang Priority hay Fast. Mình sẽ chia request thành ba rổ:
- Standard mặc định cho dev, batch, tác vụ có retry, tính năng chưa chứng minh giá trị.
- Priority có chủ đích cho request user-facing quan trọng, nơi overload làm hỏng trải nghiệm hoặc ảnh hưởng doanh thu.
- Fast sau khi đo cho flow mà model serving thật sự là nút nghẽn throughput.
Điều kiện đổi quyết định cũng phải rõ. Nếu Standard bắt đầu tạo lỗi thấy được với user trong giờ cao điểm, đẩy flow đó lên Priority. Nếu Fast không cải thiện end-to-end latency vì bottleneck nằm ngoài model, hạ xuống và sửa pipeline. Nếu tổng tải đã đều, lớn, và cần kiểm soát sâu hơn, lúc đó mới tính dedicated capacity.
Takeaway gọn: serverless inference 2.0 không bảo bạn mua gói mạnh hơn; nó bắt bạn gọi đúng tên từng loại request. Chọn tier như gieo hạt: thứ nào cần bén rễ trong production thì chăm kỹ, thứ còn đang thử giống thì đừng tưới bằng ngân sách của cả mùa vụ.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng