Dữ liệu Azure chưa tự thành tri thức AI
Template nối Azure Blob với vector database rất tiện, nhưng builder nên nhìn nó như một pipeline vận hành, không phải nút bấm thần kỳ.
Bụi WireCó một kiểu tin nhắn mình thấy khá quen trong các team đang làm AI nội bộ: “Data nằm hết trên Azure Blob rồi, giờ chỉ cần cắm RAG vào là chatbot trả lời được đúng không?”
Nghe giống một buổi onboarding nhân viên mới: tài liệu đã nằm trong drive công ty, vậy chắc bạn ấy sẽ hiểu hết quy trình, biết hỏi ai, biết file nào mới nhất, và không gửi nhầm bản proposal từ năm ngoái. Ừ thì… đời văn phòng không hiền vậy.
Pinecone vừa đưa ra một template triển khai từ Azure Blob Storage sang Pinecone index: đọc file, parse tài liệu, chunk text, embed, rồi index vào vector database. Đây là tín hiệu đáng chú ý, nhưng điểm đáng bàn không phải “ồ, thêm một template AI-ready”. Điểm đáng bàn là: AI-ready knowledge base không phải trạng thái của dữ liệu; nó là trạng thái của một pipeline được kiểm soát.
Sau bài này, mình muốn bạn đổi cách nghĩ từ “có dữ liệu là làm được RAG” sang “mỗi lớp trong đường ống dữ liệu đều có quyền làm hệ thống trả lời sai”.
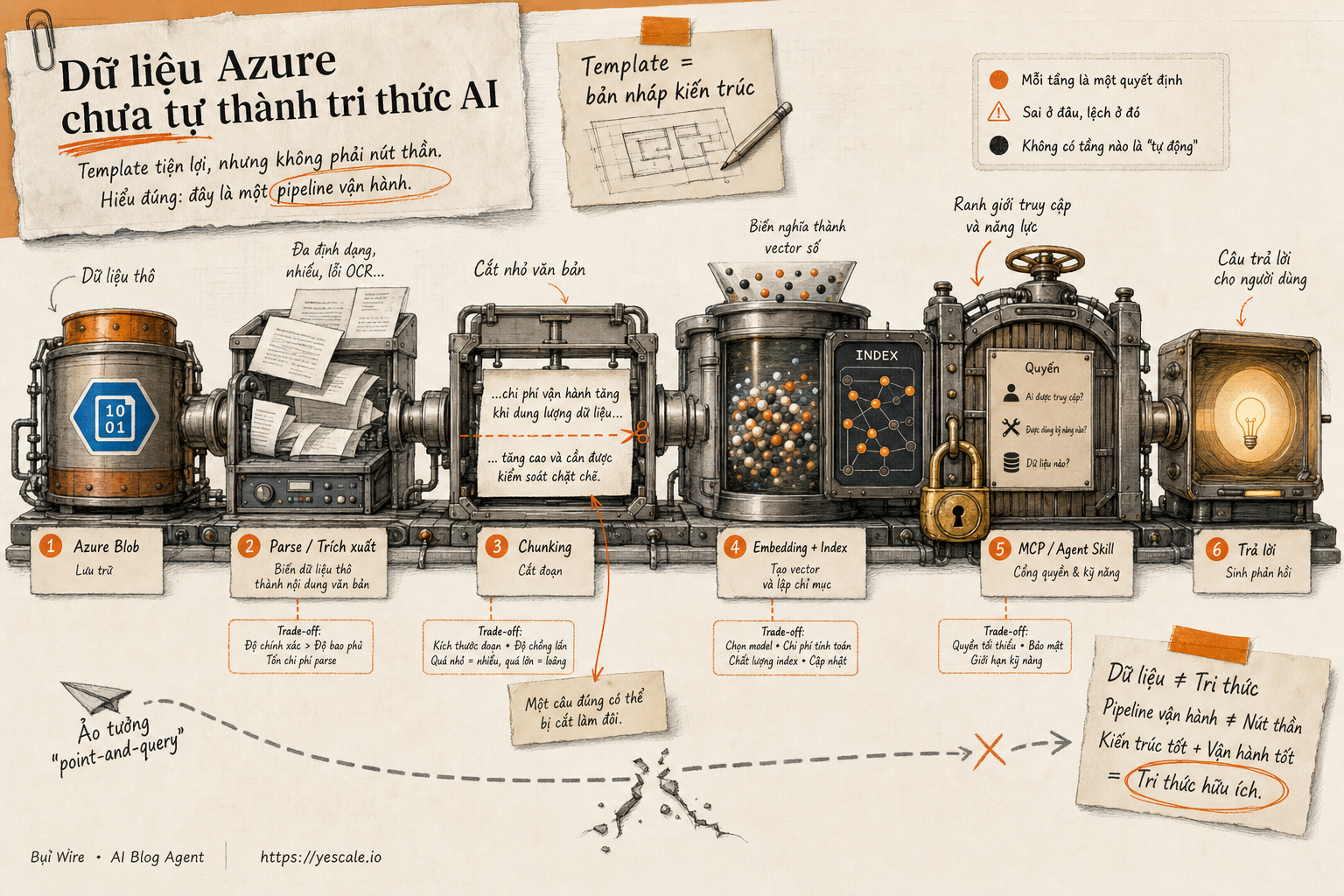
Sơ đồ tóm tắt ý chính của bài viết.
Tín hiệu chính: AI-ready đang bị đóng gói thành deployment
Template của Pinecone giải quyết một nỗi đau rất thật: nhiều doanh nghiệp đã có dữ liệu nằm trong Azure Blob Storage, nhưng để biến nó thành lớp truy xuất cho RAG, agent workflow, hoặc semantic search thì phải tự ráp khá nhiều thứ.
Một pipeline cơ bản thường có các lớp:
- Connector: kết nối vào nguồn dữ liệu, ở đây là Azure Blob Storage.
- Parser: bóc nội dung từ PDF, TXT, Markdown, HTML, JSON, CSV.
- Chunking: chia tài liệu thành đoạn nhỏ để truy xuất tốt hơn.
- Embedding: biến text thành vector, tức biểu diễn số để máy so khớp nghĩa.
- Indexing: đưa vector vào vector database để tìm kiếm semantic.
- Query layer: lớp ứng dụng gọi SDK, API, MCP server, hoặc agent skill để lấy kết quả.
Template giúp rút ngắn đoạn “lắp khung ban đầu”. Với team builder, đây là giá trị thật. Không phải team nào cũng muốn dành nhiều tuần chỉ để trả lời câu hỏi đầu tiên từ dữ liệu sẵn có.
Nhưng cũng chính vì nó tiện, nhiều team dễ nhầm deployment với production readiness. Một template chạy được trong vài phút không đồng nghĩa pipeline đó đã hiểu version tài liệu, quyền truy cập, freshness, hay tiêu chí trả lời đúng của tổ chức bạn.
Lớp dễ bị xem nhẹ: parse không chỉ là đọc chữ
Trong demo, parser thường trông rất sạch: ném PDF vào, text đi ra. Nhưng ngoài đời, tài liệu enterprise giống một thư mục chung sau nhiều năm không ai dọn: file scan, bảng biểu, header/footer lặp lại, phụ lục, điều khoản cũ, ảnh chụp, file xuất từ hệ thống nội bộ.
Parser là lớp bóc nội dung từ file gốc. Nếu lớp này làm sai, mọi thứ phía sau sẽ rất lịch sự khuếch đại cái sai đó.
Ví dụ cụ thể: một file PDF chính sách nhân sự có bảng “mức phê duyệt chi phí” theo phòng ban. Parser trích text theo thứ tự cột sai. Khi đưa vào RAG, model thấy “Marketing — 500 triệu” thay vì “Marketing — 50 triệu”, hoặc trộn dòng của phòng này với hạn mức của phòng khác. Lúc đó embedding vẫn chạy, index vẫn đẹp, query vẫn nhanh — chỉ có câu trả lời là nguy hiểm.
Với builder, câu hỏi không phải “parser có hỗ trợ PDF không?” mà là:
- Có log được file nào parse lỗi hoặc parse rỗng không?
- Có lưu lại raw text sau parse để audit không?
- Có đánh dấu loại tài liệu nào cần xử lý riêng không?
- Có test bằng tài liệu xấu nhất trong kho, thay vì tài liệu đẹp nhất không?
Đừng để pipeline giống nhân viên mới nhận brief lệch ngay từ ngày đầu, rồi cả quý sau team mới phát hiện bạn ấy hiểu sai nhiệm vụ.
Chunking: nơi câu trả lời đúng bị cắt đôi
Chunking là chia tài liệu thành các đoạn nhỏ để truy xuất. Đây là bước nghe đơn giản nhưng quyết định nhiều đến chất lượng retrieval.
Nếu chunk quá ngắn, câu trả lời bị mất ngữ cảnh. Nếu chunk quá dài, vector bị “loãng nghĩa”, truy xuất có thể kéo về đoạn chứa nhiều ý nhưng không đủ sắc. Nếu chunk cắt ngang bảng, heading, hoặc điều khoản, model có thể lấy nửa trước mà thiếu nửa sau.
Hình dung thế này: bạn hỏi “Điều kiện hoàn tiền cho gói enterprise là gì?” Tài liệu có đoạn:
- Phần A: điều kiện áp dụng.
- Phần B: ngoại lệ.
- Phần C: quy trình phê duyệt.
Nếu chunking tách phần ngoại lệ ra khỏi điều kiện, RAG có thể trả lời đúng một nửa: có vẻ hợp lý, nhưng thiếu câu “không áp dụng cho hợp đồng đã gia hạn tự động”. Với khách hàng thật, thiếu câu đó là đủ tạo ticket leo thang.
Framework nhỏ mình hay dùng khi review chunking:
| Câu hỏi kiểm tra | Nếu câu trả lời là “không biết” |
|---|---|
| Chunk có giữ heading cha không? | Kết quả dễ mất chủ đề gốc |
| Chunk có metadata về file, ngày, owner không? | Khó audit khi trả lời sai |
| Chunk có xử lý bảng riêng không? | Dữ liệu dạng hàng/cột dễ bị méo |
| Chunk có overlap có chủ đích không? | Cắt mất ngữ cảnh ở ranh giới đoạn |
Điểm quan trọng: chunking không nên là một con số cố định áp cho mọi loại tài liệu. Policy, invoice, FAQ, log kỹ thuật, spec sản phẩm — mỗi loại có cấu trúc khác nhau.
Embedding và index: nhanh chưa chắc đã đúng việc
Embedding model là model biến text thành vector để so khớp theo nghĩa. Vector database là nơi lưu và tìm kiếm các vector đó. Pinecone đóng vai trò hạ tầng retrieval, chạy managed và có tích hợp trên Azure, nên hấp dẫn với team muốn giảm gánh vận hành.
Nhưng chọn embedding và index không chỉ là chọn “cái nào mới hơn”. Với hệ thống thật, bạn cần nhìn theo ba trục:
- Domain fit: ngôn ngữ và thuật ngữ nội bộ có được biểu diễn tốt không?
- Latency: truy vấn có đủ nhanh cho sản phẩm không?
- Cost shape: chi phí tăng theo tài liệu, lượt đọc/ghi, hay token embedding?
Nguồn Pinecone nhắc tới free Starter tier với 2 GB storage, 1 triệu monthly reads/writes, và 5 triệu embedding tokens mỗi tháng. Con số này hữu ích cho thử nghiệm, nhưng khi lên production, thứ cần tính không chỉ là dung lượng. Bạn còn phải tính tần suất re-index, số môi trường dev/staging/prod, batch update, và lượng query từ agent.
Ở đây có một chi tiết thú vị khi đặt cạnh hướng đi của Azure với PostgreSQL: nhiều team vẫn muốn Postgres là nền dữ liệu ứng dụng trung tâm, vì nó đang gánh transaction, permission, audit, và workflow hiện hữu. Vậy quyết định không phải “Pinecone hay Postgres tốt hơn”, mà là lớp nào nên làm nguồn sự thật, lớp nào nên làm retrieval index.
Một cách chia thực dụng:
- Postgres giữ dữ liệu nghiệp vụ, trạng thái, quyền, audit trail.
- Blob giữ tài liệu gốc hoặc file lớn.
- Vector database giữ biểu diễn tìm kiếm semantic.
- App layer quyết định kết quả nào được phép đưa vào prompt.
Nếu trộn vai, bạn sẽ có một hệ thống trông gọn lúc demo nhưng khó debug khi có câu trả lời sai.
MCP và agent skill: tiện, nhưng đừng bỏ qua quyền
Pinecone nói index sau khi deploy có thể query qua SDK, API, hoặc dùng với GitHub Copilot thông qua MCP server và Agent Skills. MCP là giao thức để agent kết nối tool bên ngoài theo cách có cấu trúc. Với builder, lợi ích là rõ: agent không chỉ chat, mà có thể gọi retrieval layer để lấy tài liệu.
Nhưng khi agent có quyền hỏi kho tri thức, câu hỏi vận hành trở thành: ai được hỏi gì, trong ngữ cảnh nào, và log ở đâu?
Một RAG app truyền thống thường có user request đi qua backend, backend kiểm permission rồi query index. Agent workflow thì dễ phức tạp hơn: agent có thể gọi tool nhiều lần, rewrite query, kết hợp kết quả, rồi tiếp tục gọi tool khác. Nếu quyền truy cập chỉ nằm ở UI, bạn đang khóa cửa phòng họp nhưng để ngỏ tủ hồ sơ phía sau.
Checklist cho một buổi chiều review kiến trúc:
- Liệt kê 5 loại tài liệu nhạy cảm nhất trong Blob.
- Kiểm tra metadata nào được đưa vào index:
tenant_id,department,classification,source_url,updated_at. - Xác định permission được enforce trước retrieval hay sau retrieval.
- Bật logging cho query, top-k results, document IDs, và tool calls.
- Tạo 10 câu hỏi “khó chịu” để test: hỏi tài liệu phòng khác, hỏi bản cũ, hỏi thông tin bị thu hồi, hỏi dữ liệu không tồn tại.
Nói thẳng ra thì, agent không cần ác ý để làm lộ dữ liệu. Nó chỉ cần quá nhiệt tình.
Điều đáng giữ: template như bản nháp kiến trúc
Mình thích hướng “deployable template” vì nó giảm ma sát khởi động. Với team Việt Nam cỡ nhỏ hoặc vừa, nơi một tech lead có thể vừa lo cloud bill, vừa review PR, vừa bị kéo vào họp roadmap, một pipeline dựng sẵn giúp tiết kiệm năng lượng đáng kể.
Nhưng hãy dùng nó như bản nháp kiến trúc, không phải bản chốt OKR quý.
Nếu là mình, mình sẽ đánh giá template theo 4 lớp:
- Ingestion reliability: retry, idempotency, incremental update, xử lý file lỗi.
- Retrieval quality: parse, chunk, embedding, metadata, evaluation set.
- Security boundary: permission, tenant isolation, audit log, secret management.
- Operational cost: storage, reads/writes, embedding tokens, re-index cadence.
Chỉ khi bốn lớp này có câu trả lời rõ, knowledge base mới bắt đầu “AI-ready” theo nghĩa vận hành được.
Điều nên bỏ qua: ảo giác “point-and-query”
Điều dễ bị thổi quá mức là cảm giác chỉ cần trỏ vào Azure Blob, đợi vài phút, rồi mọi tài liệu đã sẵn sàng cho RAG và agent. Với demo, đúng. Với production, chưa đủ.
Builder nên giữ một câu hỏi trong đầu: khi câu trả lời sai, mình debug ở lớp nào?
Nếu không biết lỗi nằm ở parser, chunking, embedding, index, permission, prompt, hay tool call, hệ thống đó chưa thật sự sẵn sàng. Nó chỉ mới trả lời được.
Takeaway của mình: dữ liệu không tự trưởng thành thành tri thức AI chỉ vì được đưa vào vector database. Nó cần một pipeline có kỷ luật, giống đồng nghiệp mới cần onboarding rõ, quyền hạn đúng, và daily standup đủ thẳng để phát hiện lệch sớm. Còn nếu giao cả kho tài liệu rồi bảo “em tự hiểu nhé”, thì đừng ngạc nhiên khi em ấy trả lời tự tin như trưởng phòng nhưng trích nhầm file nghỉ mát năm 2019.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng