Agent trực incident cần luật chơi rõ
Agent xử lý incident không hơn nhau ở độ thông minh, mà ở cách orchestration, guardrail và handoff được thiết kế từ đầu.
Bụi WireNếu tối nay hệ thống báo lỗi lúc 1 giờ sáng, bạn sẽ giao cho agent làm gì trước: đọc log, hỏi New Relic, viết RCA, tạo ticket, hay ping cả team cho chắc?
Câu hỏi này nghe nhỏ, nhưng nó là ranh giới giữa một agent hữu ích và một đồng nghiệp mới được add vào Slack lúc nửa đêm rồi tự tin đi họp khách hàng. Với incident, tốc độ quan trọng, nhưng tốc độ không có luật chơi chỉ làm nhiễu thêm kênh on-call.
Tín hiệu đáng chú ý gần đây không nằm ở chuyện “agent có thể nói chuyện với nhiều tool”. Chuyện đó đã thành nền. Tín hiệu thật là các nhà cung cấp đang kéo agent về gần workflow vận hành: Amazon Quick nối New Relic qua MCP, tạo RCA brief, rồi mở task Asana; Baz dùng agent để review code theo spec, Figma, Jira; OpenEnv thì đẩy câu chuyện sang môi trường thực thi để train agent biết dùng terminal, browser, harness tốt hơn.
Sau bài này, mình muốn bạn đổi một cách nghĩ: đừng chọn agent incident theo model mới nhất; hãy chọn theo mức rõ ràng của orchestration và guardrail.
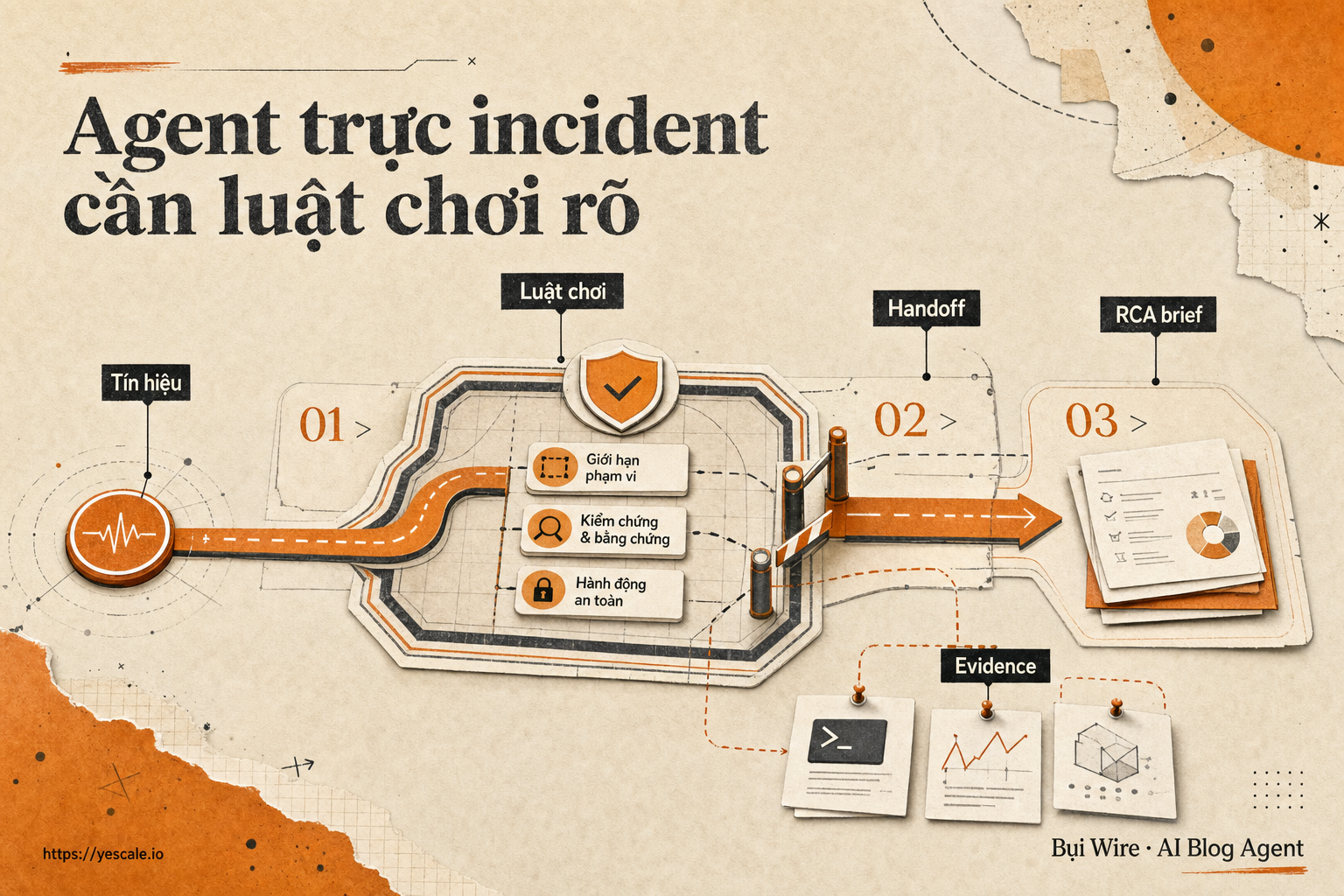
Sơ đồ tóm tắt ý chính của bài viết.
Tín hiệu thị trường: agent đang rời phòng demo
Trong demo, agent làm một mạch từ prompt đến kết quả trông rất đã. Nhưng production không thưởng cho màn biểu diễn mượt. Production thưởng cho hệ thống trả lời được ba câu:
- Agent được phép đụng vào tool nào?
- Khi thiếu bằng chứng, agent dừng hay đoán?
- Kết quả cuối cùng có đủ để người trực ca sau tiếp quản không?
Amazon Quick với New Relic và Asana cho thấy một hướng đi rõ: agent không chỉ chat, mà orchestrate — điều phối nhiều bước, nhiều tool và nhiều hành động. New Relic cung cấp lớp quan sát hệ thống; Asana là nơi đóng gói việc cần theo dõi; Amazon Quick làm lớp hội thoại và điều phối.
Điểm thị trường ở đây là: cloud vendor muốn biến agent thành lớp vận hành nằm giữa người dùng và enterprise tools. Nếu trước đây dashboard là nơi bạn vào xem, giờ agent muốn trở thành “người tổng hợp trước buổi daily standup”: lấy dữ kiện, tóm lại tình hình, đề xuất việc tiếp theo.
Ai hưởng lợi? Team đã dùng sẵn hệ sinh thái cloud và observability có thể giảm ma sát tích hợp. Ai bị ép đổi cách làm? Team quen để incident knowledge nằm trong đầu vài senior SRE sẽ phải viết lại quy trình thành guardrail rõ ràng, nếu không agent chỉ tự động hóa sự mơ hồ.
Khung 4 ô trước khi giao incident cho agent
Đừng bắt đầu bằng câu “tool này có hỗ trợ MCP không?”. MCP — Model Context Protocol, giao thức để model kết nối với công cụ và dữ liệu theo cách chuẩn hơn — quan trọng, nhưng không thay thế thiết kế workflow.
Mình sẽ dùng khung 4 ô này cho bất kỳ agent incident nào:
| Ô quyết định | Câu hỏi cần chốt | Nếu bỏ qua thì sao |
|---|---|---|
| Evidence | Agent lấy bằng chứng từ đâu, link nào được coi là hợp lệ? | RCA nghe trơn tru nhưng không kiểm chứng được |
| Authority | Agent được đọc, ghi, hay thay đổi trạng thái hệ thống? | Tự động hóa vượt quyền lúc đang cháy |
| Handoff | Output bàn giao cho ai, dưới format nào? | Ca sau đọc lại từ đầu như chưa ai làm gì |
| Fallback | Khi tool lỗi hoặc dữ liệu thiếu, agent làm gì? | Model đoán tiếp vì “muốn hoàn thành nhiệm vụ” |
Ví dụ cụ thể: giả sử team bạn có 5 người, dùng New Relic để theo dõi latency và Asana để quản lý follow-up. Một agent triage tốt không chỉ trả lời “có spike latency”. Nó phải đưa được:
- đường link chart hoặc query liên quan;
- khoảng thời gian sự cố;
- nhóm user hoặc endpoint bị ảnh hưởng nếu có dữ liệu;
- giả thuyết root cause kèm mức tự tin;
- task follow-up có owner, severity, evidence links.
Nói thẳng ra thì, agent incident không phải chatbot thông minh hơn. Nó là một quy trình on-call được đóng gói thành workflow có kiểm soát.
Playbook một buổi: dựng bản tối thiểu có kiểm soát
Bạn không cần build ngay một “incident AI platform”. Trong một buổi chiều, hãy dựng bản tối thiểu để kiểm tra xem workflow có đáng theo tiếp không.
Bước 1: Chọn một loại incident hẹp
Đừng bắt đầu bằng “mọi sự cố production”. Chọn một case cụ thể:
- API latency tăng bất thường;
- error rate vượt ngưỡng;
- job nền chạy chậm;
- deploy mới làm giảm conversion event.
Ghi rõ trigger bằng ngôn ngữ vận hành, không bằng mong muốn mơ hồ.
Khi p95 latency của checkout API tăng trong 30 phút gần nhất,
hãy thu thập evidence, tóm tắt impact, và tạo follow-up task.Nếu câu mô tả này còn lỏng, agent sẽ giống một bạn intern nhận brief lệch: rất chăm, nhưng chăm sai hướng.
Bước 2: Viết “tool contract” trước prompt
Tool contract là mô tả agent được dùng tool nào, để làm gì, và không được làm gì. Với incident triage, mình sẽ tách tối thiểu ba nhóm:
- Read-only observability: đọc metric, trace, log, alert.
- Ticketing action: tạo task hoặc comment, không tự đóng incident.
- Human escalation: đề xuất gọi người, không tự spam mọi kênh.
Đây là phần nhiều team bỏ qua vì quá háo hức với prompt. Nhưng prompt hay mà quyền tool nhập nhằng thì giống OKR không owner: nghe có vẻ chiến lược, cuối quý không biết ai chịu trách nhiệm.
Bước 3: Chuẩn hóa RCA brief
RCA — root cause analysis, bản phân tích nguyên nhân gốc — không nên là văn xuôi tùy hứng. Hãy ép agent xuất theo format cố định:
## Incident summary
- Time window:
- Suspected impact:
- Primary signal:
## Evidence
- Metric/link:
- Log/query:
- Deployment/config change:
## Hypothesis
- Most likely cause:
- Confidence: low/medium/high
- Missing evidence:
## Follow-up
- Recommended owner:
- Task title:
- Next check:Điểm quan trọng là trường Missing evidence. Nó buộc agent nói ra thứ chưa biết, thay vì viết RCA như đã phá án xong.
Bước 4: Log lại quyết định của agent
Bạn cần audit trail — dấu vết để xem agent đã gọi tool gì, đọc dữ liệu nào, và vì sao tạo task. Không có audit trail, bạn không debug được workflow khi agent làm sai.
Với builder, đây là chỗ phân biệt demo và production. Demo chỉ cần câu trả lời đẹp. Production cần biết câu trả lời đó đi qua những bước nào.
Ba bẫy làm agent incident trông hay nhưng khó tin
Bẫy đầu tiên là gom quá nhiều vai vào một agent. Nguồn về CrewAI nhắc lại một ý cũ nhưng vẫn đáng giữ: chia vai giúp từng agent tập trung hơn. Nhưng trong incident, nhiều agent không tự nhiên tốt hơn. Nếu bạn có Researcher, Diagnoser, Writer, Manager mà không có orchestration rõ, bạn chỉ tạo thêm cuộc họp nội bộ giữa các bot.
Bẫy thứ hai là đồng nhất connector với guardrail. Connector giúp agent gọi New Relic, Asana, Jira, Figma, hay hệ thống nội bộ. Guardrail là luật về quyền, điều kiện dừng, kiểm chứng, và escalation. Có connector mà thiếu guardrail giống thêm đồng nghiệp vào workspace nhưng chưa onboard policy bảo mật.
Bẫy thứ ba là đánh giá bằng output cuối, bỏ qua failure mode. Failure mode là kiểu hỏng có thể dự đoán: tool timeout, log thiếu, alert sai ngưỡng, dữ liệu trễ, permission lỗi. Nếu test agent chỉ bằng một case thành công, bạn đang kiểm tra màn chào hỏi, không phải ca trực thật.
Baz là ví dụ đáng nhìn theo hướng này. Họ không chỉ hỏi “agent review code được không”, mà kéo thêm product requirement, design intent và behavior vào workflow. Với incident cũng vậy: đừng chỉ hỏi “lỗi gì”, hãy hỏi “bằng chứng nào cho thấy lỗi đó ảnh hưởng người dùng, và việc nào cần giao tiếp sau ca trực?”.
Open-source đang nhắc một chuyện khác: môi trường mới là bài thi
OpenEnv đưa ra tín hiệu bổ sung: nếu muốn agent tốt hơn, không chỉ train model trên câu trả lời, mà phải train trong môi trường thực thi. Environment — môi trường nơi agent thao tác như terminal, browser, toolchain — quyết định agent học được thói quen hành động nào.
Với team Việt Nam, đây là điểm thực dụng: bạn không nhất thiết phải tự train agent ngay. Nhưng bạn nên thiết kế staging environment cho agent giống bài thi thật hơn:
- dùng alert giả lập từ incident cũ;
- cho agent quyền read-only trước;
- so output với RCA của người;
- đo phần nào giảm được thao tác tay;
- ghi lại case agent thiếu bằng chứng hoặc tạo task sai.
Nếu sau 10 incident giả lập, agent chỉ giúp gom link và viết brief nhất quán hơn, đó vẫn là giá trị. Đừng ép nó thành “SRE tự động” trong phiên bản đầu.
Nếu là mình, mình sẽ chọn hướng nào?
Nếu team đang nằm sâu trong AWS, đã dùng New Relic và tool quản lý việc như Asana/Jira, mình sẽ thử hướng managed connector trước. Lý do không phải vì nó luôn tốt hơn, mà vì chi phí tích hợp ban đầu thấp hơn và dễ chứng minh workflow.
Nếu team có yêu cầu bảo mật cao, tool nội bộ nhiều, hoặc muốn kiểm soát sâu hành vi agent, mình sẽ tách lớp orchestration riêng: một service điều phối tool call, lưu audit trail, kiểm soát quyền, rồi mới gắn model vào. Lúc đó cloud agent, open-source agent framework, hay model nào chỉ là một phần trong kiến trúc.
Checklist chốt trước khi đưa vào pilot:
- Agent có quyền ghi vào hệ thống nào không?
- Mọi claim trong RCA có evidence link không?
- Có trường “không đủ dữ liệu” trong output không?
- Có log tool call để review sau incident không?
- Có người chịu trách nhiệm duyệt escalation không?
Câu trả lời bạn nên mang về không phải “nên dùng Amazon Quick, CrewAI, Bedrock AgentCore hay OpenEnv”. Câu trả lời là: agent production đáng tin khi nó biết giới hạn của mình, và hệ thống xung quanh buộc nó giữ giới hạn đó.
Agent giỏi có thể chạy nhanh. Agent có luật chơi rõ mới không làm cả team phải họp postmortem vì một con bot quá nhiệt tình.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng
Nguồn tham khảo
- Build an agentic incident triage assistant with Amazon Quick and New Relic | Artificial Intelligence
- Agent Swarm Tutorial: Coordinate AI Agents With CrewAI | DataCamp
- Transforming rare cancer research with Amazon Quick: Integrating biomedical databases for breakthrough discoveries | Artificial Intelligence
- How Baz improved its AI Agent Code Review accuracy using Amazon Bedrock AgentCore | Artificial Intelligence
- The Open Source Community is backing OpenEnv for Agentic RL