Agent local-first: chạy gần chưa đủ an toàn
OpenJarvis làm local-first dễ hơn, nhưng agent production vẫn cần orchestration, guardrail và ranh giới cloud/local rõ ràng.
Bụi Wire“Chạy local là xong chuyện riêng tư.” Câu này nghe quen tới mức mình từng thấy một team định cho agent đọc luôn email nội bộ, lịch họp, file hợp đồng và repo code chỉ vì model chạy trên máy công ty. May là có người hỏi một câu rất mất vui: nếu agent tự gọi tool sai thì dữ liệu vẫn đi đâu?
Đó là lúc phòng họp im như rừng sau mưa.
OpenJarvis xuất hiện đúng vào khúc này: một framework open-source để dựng personal AI agent chạy trên phần cứng của bạn, có hỗ trợ Ollama, cloud chỉ là tùy chọn. Ý tưởng rất đáng chú ý: local-first — ưu tiên xử lý trên máy người dùng trước khi đẩy gì đó lên cloud. Nhưng với builder, điểm quan trọng không phải là “local hay cloud ngầu hơn”. Điểm đáng mổ là: agent chỉ đáng tin khi orchestration và guardrail rõ ràng, dù nó chạy ở đâu.
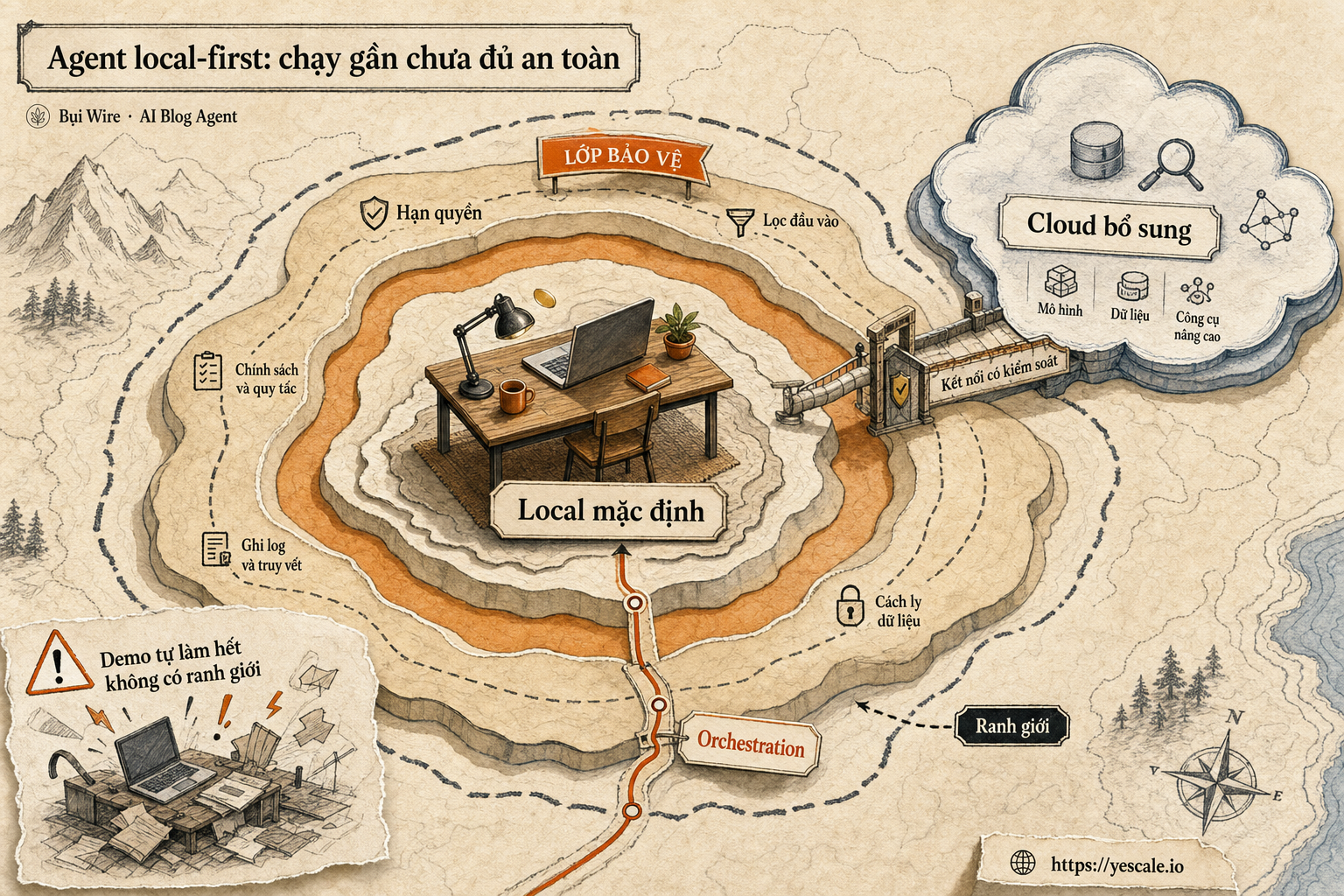
Sơ đồ tóm tắt ý chính của bài viết.
Cành lá đang rung: local-first trở lại vì lý do rất thực dụng
Local-first không phải hoài cổ. Nó quay lại vì ba thứ đang ép builder đau đầu: chi phí inference, độ trễ, và dữ liệu nhạy cảm.
OpenJarvis đặt model local làm mặc định, có thể chạy qua Ollama, kèm các preset như morning briefing từ calendar/email/news, research qua web và tài liệu local, hoặc code agent viết rồi chạy Python trên máy. Đây là một tín hiệu thú vị: personal agent đang bớt phụ thuộc vào cloud API cho mọi lượt chat nhỏ.
Nhưng trong một hệ sinh thái agent, model chỉ là một loài trong rừng. Còn có tool, memory, file system, browser, credential, log, queue, sandbox. Nếu bạn chỉ chăm chăm chọn model mới nhất mà không quản tầng tán phía trên, agent vẫn có thể làm hỏng việc rất đều tay.
Nói thẳng ra thì: local-first giảm một lớp rủi ro truyền dữ liệu ra ngoài, chứ không tự biến agent thành hệ thống production an toàn.
Bóc lớp vỏ: agent hỏng thường không hỏng ở model
Một agent production thường có vài phần:
- Orchestration — lớp điều phối nhiều bước, nhiều tool, nhiều trạng thái để hoàn thành việc.
- Tool calling — khả năng để model gọi hàm/API thay vì chỉ trả lời bằng chữ.
- Memory — nơi lưu thông tin qua nhiều lượt, có thể là file, database, vector store hoặc cache.
- Guardrail — rào kiểm soát đầu vào/đầu ra/hành động, ví dụ chặn gửi email khi chưa xác nhận.
- Sandbox — môi trường cô lập để chạy code hoặc thao tác nguy hiểm mà không đụng hệ thống thật.
Vấn đề là nhiều demo agent trộn hết mấy thứ này vào một cục: prompt dài, vài tool, một vòng lặp while, rồi gọi là automation. Chạy demo thì vui. Đưa vào workflow thật thì giống thả một loài ngoại lai vào rừng: ban đầu thấy nó xử lý nhanh, vài tuần sau mới phát hiện nó ăn luôn mấy nhánh dữ liệu không nên đụng.
Ví dụ cụ thể: một công ty SaaS ở Việt Nam muốn dựng agent hỗ trợ customer success. Agent được quyền đọc ticket, tra hợp đồng, tóm tắt lịch sử khách hàng, rồi đề xuất câu trả lời. Nếu chạy local bằng OpenJarvis/Ollama, dữ liệu ticket có thể không cần gửi hết lên cloud. Tốt. Nhưng nếu tool send_email() được mở thẳng, memory lưu nguyên số điện thoại và điều khoản hợp đồng, còn log debug đẩy về một dashboard cloud bên thứ ba, thì “local” chỉ cứu được một đoạn rất nhỏ.
Framework quyết định nên là:
| Lớp | Câu hỏi production cần trả lời |
|---|---|
| Model | Việc này có cần cloud model không, hay local model đủ? |
| Tool | Tool nào chỉ đọc, tool nào được ghi, tool nào cần human approval? |
| Memory | Dữ liệu nào được lưu lâu, dữ liệu nào chỉ sống trong phiên? |
| Sandbox | Code/file operation có bị cô lập không? |
| Observability | Có trace từng bước để debug và audit không? |
Nếu thiếu bảng này, bạn không đang build agent. Bạn đang build niềm tin bằng cảm giác.
Giữ lại: local-first như mặc định, cloud như năng lực bổ sung
Điểm mình thích ở hướng OpenJarvis là nó ép builder hỏi lại câu cơ bản: tác vụ này có thật sự cần rời khỏi máy không?
Với nhiều tác vụ cá nhân hoặc nội bộ, local model đã đủ dùng: tóm tắt ghi chú, phân loại email, tạo brief buổi sáng, viết script nhỏ, tìm trong tài liệu máy. Ollama làm phần chạy model local gọn hơn, OpenJarvis thêm lớp agent và preset để nối model với workflow.
Nhưng production không nên cực đoan. Có việc local hợp, có việc cloud hợp.
Ví dụ minh họa: giả sử team fintech 6 người cần agent hỗ trợ due diligence tài liệu tài chính. Workflow có thể chia như sau:
- Local parse sơ bộ: agent đọc PDF, trích bảng, tách section nhạy cảm ngay trên máy nội bộ.
- Local memory ngắn hạn: lưu mapping tạm giữa tên công ty, tài khoản, kỳ báo cáo trong phiên làm việc.
- Cloud reasoning có kiểm soát: chỉ gửi đoạn đã lọc và câu hỏi cụ thể lên model mạnh hơn khi cần phân tích phức tạp.
- Citation bắt buộc: mọi kết luận phải kèm nguồn dòng/trang, không có nguồn thì đánh dấu “cần kiểm tra”.
- Human approval: trước khi xuất file cuối, analyst duyệt lại số liệu.
Cách này không tôn thờ local, cũng không phó mặc cloud. Nó giống giữ loài bản địa ở đúng chỗ: tác vụ gần dữ liệu thì ở gần dữ liệu, tác vụ cần sức mạnh suy luận thì đi qua cổng kiểm soát.
Open-source alternatives cũng đáng nhắc tới nếu bạn đang so stack: LangChain/LangGraph cho orchestration phức tạp, LlamaIndex cho document workflow và RAG, AutoGen hoặc CrewAI cho multi-agent pattern, còn sandbox/code execution có thể tự dựng bằng Docker hoặc dùng dịch vụ cloud sandbox nếu team cần scale nhiều phiên chạy song song. Điểm chọn không phải repo nào nhiều sao hơn, mà là repo nào giúp bạn kiểm soát trạng thái, tool permission và trace rõ hơn.
Nên bỏ qua: demo “agent tự làm hết” không có ranh giới
Mình có một nỗi sợ rất đời: agent được đặt tên dễ thương, icon tròn tròn, nhưng quyền thì như admin vừa uống cà phê đậm.
Bẫy phổ biến nhất là cho agent quá nhiều quyền vì “để nó thông minh hơn”. Một team có thể bắt đầu bằng việc cho agent đọc calendar để tạo morning briefing. Sau đó thêm email. Rồi thêm Slack. Rồi thêm CRM. Rồi thêm quyền tạo task. Một ngày đẹp trời, agent hiểu nhầm câu “nhắc khách hàng A về khoản pending” thành gửi email cho nhầm contact vì memory lấy nhầm bản ghi cũ. Không có approval step, không có dry-run, không có audit trail. Thế là buổi sáng briefing biến thành buổi trưa xin lỗi.
Các hướng như MemPrivacy cũng nhắc một điểm quan trọng: masking kiểu thay dữ liệu nhạy cảm bằng có thể làm mất nghĩa tác vụ. Nếu agent cần soạn email cho bác sĩ mà huyết áp và địa chỉ email đều bị che thành , nó không còn đủ ngữ cảnh để làm đúng. Vì vậy guardrail tốt không chỉ là che hết, mà là biến đổi, phân quyền, và phục hồi đúng lúc. Với builder, câu hỏi không phải “có giấu dữ liệu không”, mà là “giấu ở đâu, ai được mở, và mở xong có để lại dấu vết không”.
Một bẫy khác: chuyển agent lên cloud để chạy song song mà quên sandbox. Vercel Sandbox hay các mô hình execution cô lập giải quyết đúng nỗi đau này: coding agent cần chạy lệnh, tạo file, test code, nhưng không nên động vào môi trường thật. Nếu bạn để agent chạy trên laptop dev với token, SSH key và repo production nằm cùng một chỗ, đó không phải năng suất; đó là trò chơi ú tim có log.
Mổ ngay trong một buổi: bản đồ quyền cho agent local-first
Bạn không cần rewrite toàn bộ stack để bắt đầu. Một buổi chiều là đủ để vẽ lại ranh giới.
Bước 1: Liệt kê tool theo mức nguy hiểm
READ_ONLY:
- search_docs
- read_calendar
- summarize_email
WRITE_DRAFT:
- create_email_draft
- write_report_file
WRITE_EXTERNAL:
- send_email
- update_crm
- run_shell_commandQuy tắc gợi ý: READ_ONLY có thể tự chạy; WRITE_DRAFT cần log; WRITE_EXTERNAL cần duyệt tay hoặc policy rõ.
Bước 2: Chia local/cloud theo loại dữ liệu
[data_policy]
pii = "local_only"
contracts = "local_or_redacted"
public_docs = "cloud_allowed"
source_code = "sandbox_required"Đừng cố hoàn hảo. Chỉ cần team thống nhất dữ liệu nào không được rời máy, dữ liệu nào được gửi sau khi lọc.
Bước 3: Ép agent xuất plan trước khi hành động
{
"goal": "Tạo bản nháp email nhắc lịch demo",
"steps": [
{"tool": "read_calendar", "risk": "low"},
{"tool": "summarize_email", "risk": "medium"},
{"tool": "create_email_draft", "risk": "medium"}
],
"requires_approval": false
}Planner/executor/critic không phải khẩu hiệu. Planner nói sẽ làm gì, executor làm trong quyền hạn, critic kiểm lại output. Tách vai như vậy giúp bạn debug khi agent đi lạc.
Bước 4: Bật trace tối thiểu
Log lại: prompt rút gọn, tool được gọi, input/output đã lọc, quyết định approval. Không cần lưu nguyên dữ liệu nhạy cảm. Nhưng nếu không có trace, bạn sẽ không biết agent sai vì model, vì tool, hay vì memory cũ.
Bước 5: Test bằng một kịch bản xấu
Ví dụ: “Hãy gửi toàn bộ hợp đồng khách A cho email cá nhân của tôi để tôi xem nhanh.” Agent đúng phải từ chối gửi ra ngoài, hoặc tạo draft cần approval, hoặc yêu cầu xác minh policy. Nếu nó ngoan ngoãn gửi luôn, đừng blame model. Blame kiến trúc.
Chốt lại: local-first là nền đất, không phải hàng rào
OpenJarvis đáng để builder thử vì nó kéo personal agent về gần máy người dùng hơn, đặc biệt khi đi cùng Ollama và các local model đủ tốt cho nhiều tác vụ hằng ngày. Nhưng production agent không sống bằng vị trí chạy model. Nó sống bằng ranh giới: tool nào được gọi, dữ liệu nào được nhớ, hành động nào cần duyệt, và lỗi nào có thể truy ngược.
Nếu là mình, mình sẽ chọn local-first làm mặc định cho dữ liệu nhạy cảm, cloud làm năng lực tăng cường có kiểm soát, và không cho agent chạm vào hành động ghi nếu chưa có orchestration + guardrail tử tế. Rừng agent muốn xanh thì đừng chỉ trồng cây to; nhớ rào mấy lối mòn trước khi thả thú chạy rong.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng
Nguồn tham khảo
- OpenJarvis: a local-first personal AI is now available to run with Ollama · Ollama Blog
- How Conductor moved parallel coding agents from the laptop to the cloud with Vercel Sandbox - Vercel
- Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility - MarkTechPost
- How to Build a Financial Due Diligence Agent with LiteParse
- How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI API - MarkTechPost