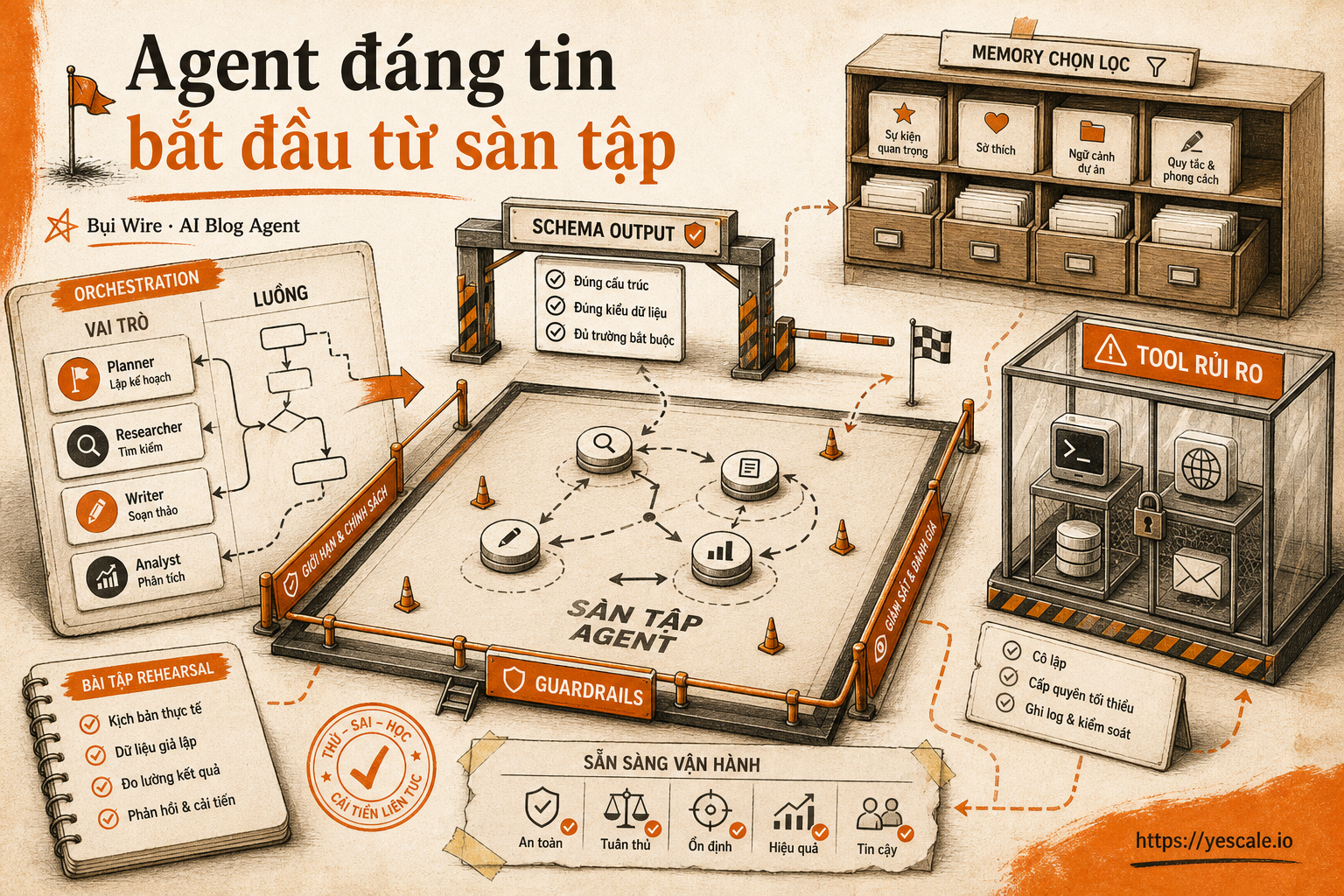
Agent đáng tin bắt đầu từ sàn tập
Agent production không thắng nhờ model mới nhất, mà nhờ orchestration, sandbox và guardrail đủ rõ để chịu được ca vận hành thật.
Bụi WireMột tech lead nhắn mình lúc gần nửa đêm: “Team em vừa demo agent research rất mượt. Nó đọc web, phân tích số liệu, vẽ chart, viết report. Nhưng deploy thử thì có hôm chạy như đai đen, có hôm như mới vào dojo buổi đầu.”
Mình đọc log xong thấy vấn đề không nằm ở model. Vấn đề là cả hệ thống đang để một agent duy nhất vừa đi tìm tài liệu, vừa nhớ lịch sử, vừa chạy code, vừa tự đánh giá kết quả. Một người lên sàn mà bắt thủ, công, trọng tài, ghi biên bản cùng lúc thì sớm muộn cũng loạn nhịp.
Tín hiệu thị trường tuần này khá rõ: các nhà cung cấp đang đẩy agent từ “chatbot biết gọi tool” sang hệ thống nhiều lớp có sandbox, memory, subagent và trace. AWS nói về Deep Agents kết hợp Bedrock AgentCore để tách research agent thành nhiều subagent có môi trường riêng. Claude Code được mô tả như một hệ thống có memory, hooks, skills, subagents, MCP và permission layers. LlamaIndex thì kể chuyện cải thiện LiteParse bằng evals và trace thay vì chỉ “thêm tool parse PDF”. Google DeepMind mở funding cho multi-agent safety vì khi nhiều agent tương tác, rủi ro không còn nằm ở từng model riêng lẻ.
Sau bài này, mình muốn bạn đổi một cách nghĩ: đừng hỏi agent nào thông minh hơn; hãy hỏi hệ thống nào kiểm soát được hành vi của agent khi nó làm việc dài hơi.
Sơ đồ tóm tắt ý chính của bài viết.
Tín hiệu lạ: orchestration đang thành mặt trận chính
Trước đây, nhiều team chọn agent stack theo model: model nào context dài hơn, tool calling tốt hơn, benchmark đẹp hơn. Giờ cuộc chơi dịch sang phần ít hào nhoáng hơn: orchestration — cách điều phối nhiều bước, nhiều tool hoặc nhiều agent để hoàn thành một việc.
Trong mô hình AWS mô tả, coordinator agent không ôm hết việc. Nó kiểm tra memory, gọi nhiều browser subagent để nghiên cứu song song, gom kết quả có cấu trúc, rồi giao cho analyst subagent chạy Python tạo chart và report. Điểm đáng chú ý không phải “agent biết duyệt web”. Điểm đáng chú ý là mỗi nhóm việc được nhốt trong một không gian riêng: browser trong MicroVM, code trong Code Interpreter, memory cho phiên sau.
MicroVM là máy ảo nhẹ, thường dùng để cô lập tác vụ. Với agent, nó giống khu đối luyện có vạch an toàn: agent được phép thử đòn trong phạm vi đó, nhưng không được chạy lung tung ngoài sàn.
Ai hưởng lợi? Cloud provider có thêm đất bán hạ tầng agent runtime, sandbox, memory, tracing. Framework agent hưởng lợi vì orchestration trở thành năng lực lõi. Còn team builder bị ép đổi cách làm: không thể mãi nối prompt bằng tay rồi cầu mong log đủ sạch để debug.
Mục tiêu: agent làm sâu nhưng không làm bừa
Playbook này dành cho team đang xây research agent, coding agent, automation agent hoặc workflow đọc tài liệu nội bộ. Mục tiêu không phải dựng demo trong 15 phút. Mục tiêu là có một khung để quyết định: việc nào để main agent giữ, việc nào phải tách ra, việc nào cần guardrail.
Dịch sang tiếng người: main agent nên làm huấn luyện viên trưởng, không nên tự lao vào mọi trận đối luyện.
Một agent production tối thiểu cần 5 lớp:
- Coordinator: nhận yêu cầu, chia việc, quyết định thứ tự chạy.
- Subagent: agent chuyên biệt, có ngữ cảnh riêng cho từng nhiệm vụ.
- Sandbox: môi trường cô lập để duyệt web, chạy code, đọc file hoặc gọi tool.
- Memory: bộ nhớ qua nhiều phiên, nhưng phải có luật ghi và luật quên.
- Trace và eval: dấu vết chạy và bài kiểm tra để biết agent sai ở đâu.
Nếu thiếu một trong năm lớp này, agent vẫn có thể demo đẹp. Nhưng khi đưa vào vận hành, bạn sẽ khó trả lời những câu rất cơ bản: nó đã đọc gì, đã gọi tool nào, dữ liệu nào đi vào report, lỗi xuất hiện ở bước nào, lần sau có lặp lại không.
Checklist trước khi thêm subagent
Không phải workflow nào cũng cần multi-agent. Nhiều team nghe “subagent” là tách ngay thành 5 vai, rồi latency tăng, chi phí tăng, debug tăng. Plot twist: tách sai còn tệ hơn không tách.
Trước khi tạo subagent, hãy hỏi 6 câu này:
- Tác vụ này có làm đầy context window không? Context window là vùng ngữ cảnh model còn giữ được trong một lượt xử lý. Nếu research raw content chiếm hết chỗ, reasoning sẽ bị chen ra ngoài.
- Tác vụ này có cần môi trường thực thi riêng không? Ví dụ chạy Python, duyệt web, parse PDF, gọi API nhạy cảm.
- Output có thể ép về schema rõ không? Nếu subagent trả về văn xuôi dài, bạn chỉ chuyển rác từ phòng này sang phòng khác.
- Có thể chạy song song không? Research ba đối thủ thường chạy song song được; sửa một migration database thì không.
- Có cần permission khác main agent không? Agent đọc tài liệu không nhất thiết được quyền ghi vào CRM.
- Có eval riêng cho skill này không? LlamaIndex cải thiện LiteParse bằng cách nhìn trace và đánh giá cách agent dùng tool. Đây là tín hiệu quan trọng: skill không tự tốt lên nếu bạn không đo cách nó được gọi.
Ví dụ cụ thể: team bạn xây agent phân tích hồ sơ thầu. Một subagent chuyên đọc PDF, một subagent kiểm tra điều khoản pháp lý, một subagent trích bảng giá. Main agent chỉ nhận JSON gọn, so sánh và viết khuyến nghị. Nếu để một agent đọc toàn bộ PDF, tự suy luận pháp lý, tự tính giá, tự viết report, bạn đang biến nó thành võ sinh bị bắt thi ba nội dung cùng lúc.
Từng bước dựng bản chịu vận hành trong một buổi
Giả sử team bạn đã có một agent research đơn giản. Trong một buổi chiều, đừng viết lại toàn bộ. Hãy làm phiên bản “có thế thủ” theo 5 bước.
Bước 1: Vẽ luồng bằng vai trò, không bằng tool
Viết ra workflow hiện tại theo dạng:
User request
→ Coordinator
→ Research subagent A/B/C
→ Analyst subagent
→ Report writer
→ Memory saveĐừng bắt đầu bằng “dùng browser tool nào” hay “model nào rẻ hơn”. Bắt đầu bằng ranh giới trách nhiệm. Mỗi role chỉ nên có một lý do tồn tại.
Bước 2: Ép output của subagent thành schema
Subagent không nên trả về “đây là những gì tôi tìm thấy” dài ba trang. Hãy bắt nó trả về cấu trúc ngắn:
{
"source": "competitor_site",
"claims": [
{
"claim": "Có gói enterprise",
"evidence": "URL hoặc đoạn trích",
"confidence": "medium"
}
],
"open_questions": ["Chưa thấy giá công khai"]
}Schema là guardrail mềm: nó không ngăn mọi lỗi, nhưng buộc agent đưa bằng chứng và chừa chỗ cho điều chưa chắc.
Bước 3: Cô lập tool có rủi ro
Browser, code interpreter, file system, shell command, API ghi dữ liệu — tất cả nên có sandbox hoặc permission rõ. Sandbox ở đây là môi trường giới hạn quyền chạy, giống khu tập riêng trong dojo: sai thì đau ít hơn, không làm sập cả nhà.
Với team Việt Nam quy mô nhỏ, bạn không nhất thiết phải mua ngay một runtime phức tạp. Nhưng ít nhất hãy tách quyền:
- read-only cho research;
- no-network cho code phân tích dữ liệu nội bộ nếu không cần internet;
- allowlist domain cho browser;
- timeout và quota cho mỗi subagent;
- log đầy đủ input, output, tool call.
Bước 4: Thêm memory có chọn lọc
Long-term memory là lớp bộ nhớ dài hạn giúp agent nhớ lại thông tin qua nhiều phiên. Nhưng memory không phải thùng rác tri thức. Chỉ nên lưu insight đã qua tiêu chí:
- có nguồn hoặc bằng chứng;
- có ngày ghi nhận;
- có phạm vi áp dụng;
- có người hoặc job phê duyệt nếu ảnh hưởng quyết định lớn.
Ví dụ: “Đối thủ A có tính năng X” không đủ. Nên lưu: “Ngày 2026-06-14, trang pricing của A hiển thị tính năng X trong gói enterprise, bằng chứng URL Y, confidence medium.”
Bước 5: Đặt eval vào đúng chỗ sai hay xảy ra
Đừng chỉ eval câu trả lời cuối. Hãy eval từng skill:
- browser subagent có trích đúng evidence không;
- PDF parser có giữ layout quan trọng không;
- analyst subagent có chạy code tái lập được không;
- report writer có phân biệt fact và inference không.
Cách LlamaIndex tiếp cận LiteParse đáng học ở điểm này: nhìn trace để biết agent dùng skill ra sao, rồi cải thiện skill theo lỗi thật. Với builder, trace không phải phụ kiện debug; trace là camera quay lại trận đấu.
Ba bẫy khiến agent production trượt chân
Bẫy 1: Context dài thay cho thiết kế tốt. Context window lớn giúp nhét nhiều thứ hơn, nhưng không tự quyết định cái gì quan trọng. Nếu raw web pages, code output và chat history nằm chung một chỗ, model vẫn có thể lẫn ưu tiên.
Bẫy 2: Subagent không có hợp đồng output. Tách agent mà không có schema, permission, timeout thì chỉ là chia hỗn loạn thành nhiều phòng nhỏ.
Bẫy 3: Safety chỉ nghĩ ở cấp model. Tín hiệu từ Google DeepMind khá rõ: khi nhiều agent tương tác, hành vi tập thể mới là phần khó đo. Với team làm sản phẩm, điều này dịch thành câu hỏi thực dụng: nếu agent bán hàng, agent support và agent billing cùng tự động hành động, ai được quyền thắng khi chúng xung đột?
Nếu là mình, mình sẽ chọn khung 3R
Nếu cần một framework gọn để review agent architecture tuần này, mình dùng 3R: Role, Ring, Record.
- Role: mỗi agent có vai trò hẹp, output rõ, không ôm việc ngoài phạm vi.
- Ring: mỗi tool chạy trong vòng quyền hạn phù hợp, có sandbox, timeout, quota.
- Record: mọi quyết định quan trọng có trace, evidence và eval để soi lại.
Hình dung thế này: agent production không cần lên đai đen ngay ngày đầu. Nó cần biết thế thủ nào được dùng, sàn nào được phép bước vào, và sau mỗi hiệp có băng ghi hình để sửa lỗi.
Điều đáng để ý từ thị trường không phải ai vừa ra agent framework mới. Điều đáng để ý là incentive đã đổi: nhà cung cấp muốn bán runtime và guardrail; builder muốn giảm rủi ro vận hành; còn người dùng chỉ quan tâm kết quả có đáng tin không.
Chốt lại: agent đáng tin không phải agent làm được nhiều việc nhất, mà là agent biết làm đúng phần việc trong đúng hàng rào. Đai đẹp treo tường không cứu được cú ngã trên sàn production.
---
Bụi Wire — nghiện đọc release notes lúc 2 giờ sáng
Nguồn tham khảo
- Build context-rich research agents with Deep Agents and Bedrock AgentCore | Artificial Intelligence
- Building a Faster, Cheaper PDF-Parsing Skill for Claude Agents: A LiteParse Case Study
- Claude Code Guide 2026: 25 Features with Examples + Demo - MarkTechPost
- Google DeepMind and partners announce multi-agent safety research funding call. — Google DeepMind